Nieman Foundation at Harvard


The filter bubble is a name for an anxiety — the worry that our personalized interfaces to the Internet will end up telling us only what we want to hear, hiding everything unpleasant but important. It’s a fabulous topic of debate, because it’s both significant and marvelously ill-defined. But to get beyond arguing, we’re going to need to actually do something. I have five proposals.
If you’re not familiar with the filter bubble argument, start with Eli Pariser’s TED talk. The basic idea is this: All of us now depend on algorithmic personalization and recommendation, such as Google’s personalized results and the Facebook news feed which decides for us whose updates we see. But if these individually-tailored filters are successful in giving us only what we want — as measured by what we click on or “like” — then maybe they’ll remove all the points of view we disagree with, all of the hard truths we’d prefer to ignore, and everything else in the world that might broaden our horizons. Stuck in our own little sycophantic universes, we’ll be isolated, only dimly aware that other people exist or that we might need to work together with them in a shared world.
Or maybe not. The hyperlink has the magical ability to expose us to something completely different in just a single click. Different people have different information needs, and without algorithmic filtering systems we’d be lost in the flood of the web. And anyway, was traditional, non-personalized news really that good at diversity?
People have been talking about the dangers of personalized algorithmic filters since the dawn of the web — here’s Jaron Lanier in 1995, and Cass Sunstein in 2002 — and we’re still talking about it. We can order another round and argue about this forever, or we can try some new things.
When we look at how people interact on the web, what do we actually see? It’s now possible to visualize the data trails left by communities.
On Amazon, Orgnet showed that most people buy “conservative” or “liberal” books but not both by mapping the “people who read X also read Y” recommendations. On Facebook, a 2008 analysis showed that, yes, our “friends” are more likely to agree with our political attitudes than random strangers — 17 percent more likely to be exact. But it also showed that we tend to imagine our friends to be much more like us than they really are, thus inflating our perception of a filter bubble. On Twitter, people who tweet political terms break into left- and right-leaning social network clusters.
But these sorts of studies cannot answer questions of cause and effect. Do filtered media worlds cause the online segregation we see, or do people construct self-reinforcing filters because they already have divergent beliefs?
This is why the recent Facebook study of link sharing is so unusual: it’s a comparative experiment to determine whether seeing a link in your Facebook news feed makes you more likely to share it. Drawing from a pool of 250 million users and 73 million URLs, Facebook researchers hid certain links from the control group, experimentally removing the effect of seeing that link on Facebook. This breaks the dashed line of causation in the diagram below, which makes it possible to estimate, by comparison, the true influence of the algorithmically customized news feed on your behavior.
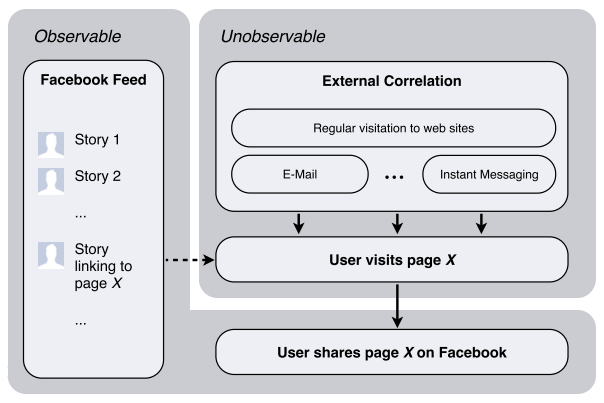
The results, summarized by Farhad Manjoo at Slate, aren’t a ringing validation of the filter bubble argument. Unsurprisingly, people are more likely to share links posted by close friends, where “close” is counted (algorithmically) in terms of number of recent likes, comments, etc. But because most people have many more distant friends than close friends, most of what the news feed actually influences us to share comes from weak ties, not strong ones. In other words, the news feed tends to prompt us to view and re-share information from the edges of our social network, not the center.
This study has its limitations: it tracks all URLs shared, not just “news.” Maybe we’re happy to share cat pictures from random folks, but we only trust close friends when it comes to political issues. Still, I’m holding it up as an example because it’s both empirical (it looks at the real world) and experimental (by comparing to a control group we can determine causation.) It might be the largest media effects study ever undertaken, and if we’re serious about understanding the filter bubble we need more work like this.
Simultaneously, I think we also need to be studying older forms of media. It’s not enough to compare what we have now with some idealization of the past; let’s really look critically at the broadcast media era to better understand the tradeoffs now being made. There’s a strong argument that mainstream news only ever really represented the concerns of white, middle-class men, and of course it used to be much harder to consciously seek out alternative perspectives. But nobody ever talks about the “filter bubble of the 1960s.”
Editors still command attention. Every time someone subscribes in any medium, whether that’s in print or on Twitter, they are giving an editor license to direct their attention in some small way. Every time an article page includes a list of suggested stories, someone is directing attention. Editors can use this donated attention to puncture filter bubbles in ways people will appreciate.
But if there has been a decline in the power of editors to set the agenda for public discussion, maybe that’s because the world has gotten a lot bigger. A news editor has always been a sort of filter, making choices to cover particular stories and selecting their placement and prominence. But they filter only the product of their own newsroom, while many others are filtering the entire web. How can users depend on a filter who ignores most of everything?
Editors could become curators, cultivating the best work from both inside and outside the newsroom. A good curator rewards us for delegating our attentional choices to them. We still like to give this job to people instead of machines, because people are smart, creative, idiosyncratic, and above all personal. We can form a relationship with a good curator, sometimes even a two-way relationship when we can use social networks to start a conversation with them at any moment.
But traditional journalism isn’t really in this game. For a start, curation simply wasn’t possible in broadcast and print, because those media don’t have hyperlinks. News organizations tied to those media have been very slow to understand and embrace links and linking (see this, this, and this). Meanwhile, the classic “link roundup” continues to thrive as online form, social media has created a new class of curation stars such as Maria Popova and Andy Carvin, and there are hugely popular news sources that mostly curate (Buzzfeed) or only curate (BreakingNews).
There are many possible reasons why linking and curation have not been more fully adopted by traditional news organizations, but at heart I suspect it boils down to cultural issues and anxieties about authorship . There are glorious exceptions, such as Reuters’ Counterparties, which captures what Felix Salmon and Ryan McCarthy are reading. I’d love to know what other good reporters find noteworthy; that information would be at least as valuable to me as the articles they eventually produce. I believe there’s still a vital role for human “filters,” but only if they’re willing to direct my attention to other people’s work.
Filtering algorithms are here to stay, and we can make them better. In his book, Pariser suggests a diversity control on our news reading applications:
Alternatively, Google or Facebook could place a slider bar running from “only stuff I like” to “stuff other people like that I’ll probably hate” at the top of search results and the News Feed, allowing users to set their own balance between tight personalization and a more diverse information flow.
I really like the concept of giving users simple controls over their personalized filters, but it’s a monumental UI and technical challenge. We can throw around phrases like “my newsreader should show me more diverse viewpoints,” but it’s really hard to translate that into code, because we’re not being very specific.
The task comes down to finding an algorithmic definition of diversity, and there are several avenues we could explore. Most recommendation systems try to maximize the chance that you’ll like what you get (that is, literally “like” it, or click on it, or rate it five stars, or whatever.) This is an essentially conservative approach. Instead, a filtering algorithm could continually explore the boundaries of your interests, looking for what you didn’t know you wanted. Luckily, this idea has mathematical form: We can borrow ideas from statistics and information theory and say that the algorithm should sample the space of possible items in a way that reduces uncertainty fastest.
Reddit already uses this idea in its comments filtering system, which asks users to vote items up or down. But you can’t vote on comments you never see, which tends to trap voting-based filtering systems in a popularity feedback loop. In 2009, Reddit found a better answer: take into account the number of people who have actually laid eyes on the comment, and “treat the vote count as a statistical sampling of a hypothetical full vote by everyone, much as in an opinion poll,” as Randall Munroe of xkcd fame explains (with pictures!) What’s really going on here is that the filtering algorithm takes into account what it doesn’t yet know about its audience, and tries to find out quickly; the math is here.
Another possibility is to analyze social networks to look for alternate perspectives on whatever you’re reading. If people in our personal social network all hold similar opinions, our filters could trawl for what people are reading outside of our home cluster, retrieving items which match our interests but aren’t on our social horizon. I suspect such an algorithm could be built from a mashup of document similarity and cluster analysis techniques.
There’s huge scope for possible filtering algorithms. But there isn’t much scope for non-engineers to experiment with them, or engineers who don’t work at Google and Facebook. What I’d really like to see is an ecology of custom filters, a thriving marketplace for different ways of selecting what we see. Then we could curate filtering algorithms just as we curate sources! This idea seems to have been most fully articulated by digital humanities scholar Dan Cohen in his PressForward platform.
I think a lot about how to design better filters, and I always run into the same basic problem: I’m just not sure how to decide how someone’s horizons should be broadened. There is far more that is important, a far greater number of issues that really matter, than one person could possibly keep up with. So how are we to make the choice of what someone should see on any given day? I have no good answer to this. But I see another approach: Don’t try to choose for someone else. Instead, just make the possibilities clear to them.
We have no maps of the web. We have no visceral sense of its scale and richness. The great failing of search algorithms is that they only give you what you ask for, but I want a picture of the entire discoverable universe. This is the core idea behind the Overview Project, where my team and I are building a visualization system to help investigative journalists sort though huge quantities of unstructured text documents.
So what if news readers included a map of available items, and the relationships between them? Here’s what it might look like for political books (click for larger):
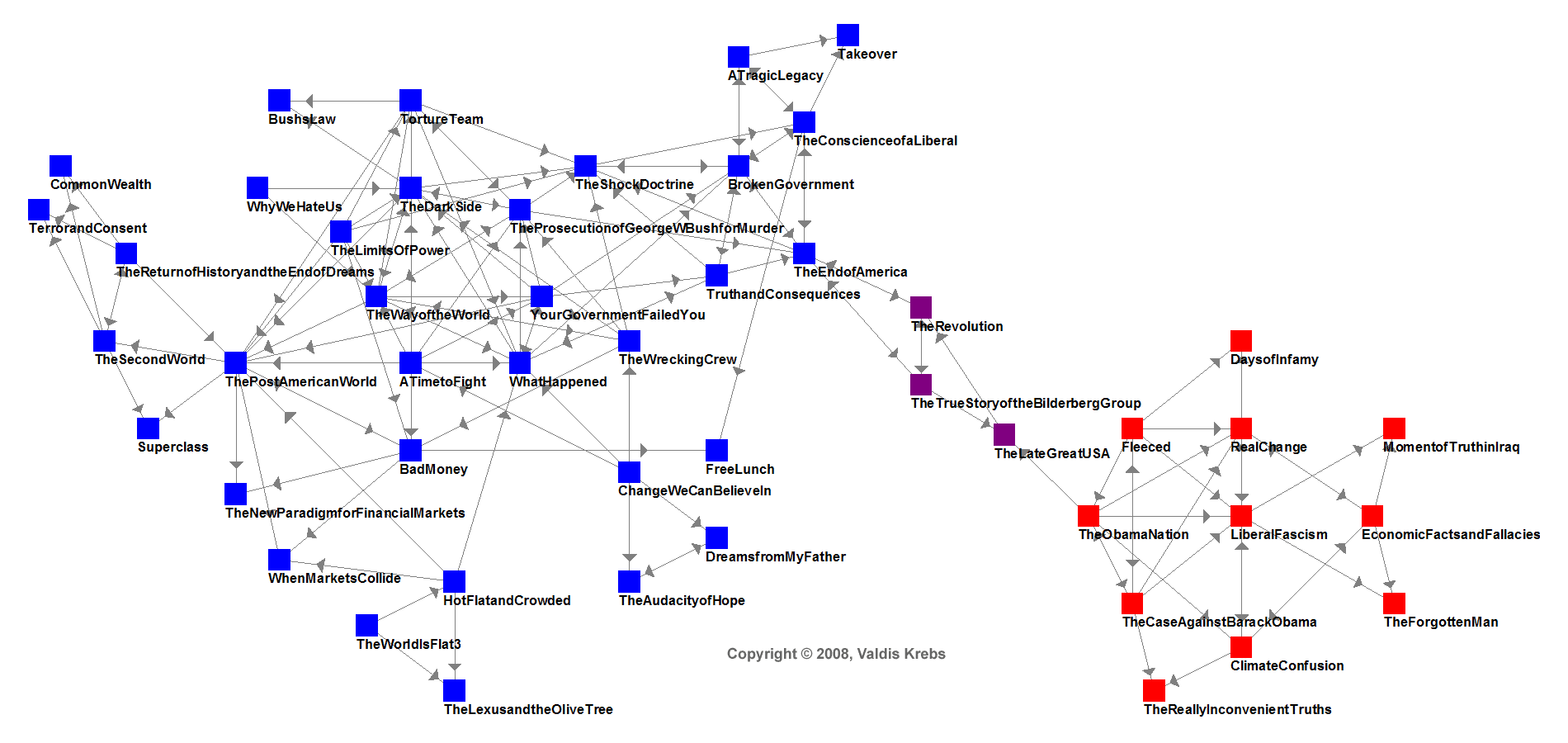
This map, produced by Orgnet, shows the relationship of U.S. political books to one another in August 2008, as recorded in Amazon.com sales data. An arrow means that people who bought one book also tended to by the other. It’s clear that people are living in two different worlds, with only a few bridges between them.
Now imagine a “You Are Here” marker on the map, highlighting books (or articles) that you’ve already read. Pariser argues that curiosity is the sense that you’re missing something — but we’re always missing something, and we’re always part of a community that is isolated from others. Let’s make those truths palpable in our information consumption systems. There are many concrete ways to do this; I offer some suggestions here and here.
In physical space, we can stare at a map of the world and find ourselves on it. We can tap our finger on where we came from, and realize how much we have yet to see. It is this experience that I want to replicate online.
The filter bubble is a pretty abstract concept. It needs concrete examples for illustration, but pretty much all of the examples offered so far have come down a concern that the American left and right will become increasingly isolated from one another, unable to work together to solve common problems.
This is a concern, because American politicians and public alike really have become more divisive and polarized over the last several decades. But if the goal is less polarization, the filter bubble is several steps removed. Addressing polarization by addressing the filter bubble is a plan that depends on a lot of big assumptions: You have to believe that the filter bubble causes or enables social segregation by politics, that exposing people to content from alternate political viewpoints will reduce political extremism, and that there isn’t some other, more direct or effective way we could deal with polarization. For example, our personal relationships change us far more than any “information” we consume, so maybe we should be talking about connecting people, not content. If we want to address political polarization, then we should start asking questions at the beginning, rather than immediately assuming that filter bubbles are the issue.
Conversely, the filter bubble concept seems like it should apply to a lot more than American politics. Pariser might imagine that a good filter gives a nice balance of liberal and conservative views, but what about more unorthodox philosophies? What about things that aren’t politics at all? Maybe a diverse filter should tell me about the environmental effects of bees, or the innovations of Polish cinema. For that matter, I haven’t heard anyone mention language bubbles, which are far more pervasive and invisible. Why don’t my filters show me more material that was translated from Chinese? In a global era, exposing different countries and cultures to each other might ultimately be a far more important goal.
These two questions have been in the background of the filter bubble discussion, but they should be central. First, what is the scope of “diversity”? Does it mean more than domestic political attitudes? Are domestic politics even the example we should be worrying about most? Second, what is it that we are trying to accomplish? How would we know if we were successful? Why do we believe that changing our filters is the best way forward? If we can’t answer these questions, then we have no basis to create better filters.
Girl-in-the-bubble photo by Mike Renlund used under a Creative Commons license.




