Nieman Foundation at Harvard
Crowdsourcing efforts like this one have a spotty history in journalism. For every project that gains traction among a news site’s audience, there’s another that never really took off. What distinguishes the ones that succeed from the ones that don’t?
With the election now past, ProPublica’s Amanda Zamora took a look back at how Free the Files fared — $1 billion in ad spending logged, almost 1,000 volunteers working on it — and what broader lessons might be drawn for other journalistic crowdsourcing. Here’s her piece, republished from ProPublica.
 This fall, ProPublica set out to Free the Files, enlisting our readers to help us review political ad files logged with Federal Communications Commission. Our goal was to take thousands of hard-to-parse documents and make them useful, helping to reveal hidden spending in the election.
This fall, ProPublica set out to Free the Files, enlisting our readers to help us review political ad files logged with Federal Communications Commission. Our goal was to take thousands of hard-to-parse documents and make them useful, helping to reveal hidden spending in the election.
Nearly 1,000 people pored over the files, logging detailed ad spending data to create a public database that otherwise wouldn’t exist. We logged as much as $1 billion in political ad buys, and a month after the election, people are still reviewing documents. So what made Free the Files work?
A quick backstory: Free the Files actually began last spring as an effort to enlist volunteers to visit local TV stations and request access to the “public inspection file.” Stations had long been required to keep detailed records of political ad buys, but they were only available on paper and required actually traveling to the station.
In August, the FCC ordered stations in the top 50 markets to begin posting the documents online. Finally, we would be able to access a stream of political ad data based on the files. Right?
Wrong. It turns out the FCC didn’t require stations to submit the data in anything that approaches an organized, standardized format. The result was that stations sent in a jumble of difficult to search PDF files. So we decided if the FCC or stations wouldn’t organize the information, we would.
Enter Free the Files 2.0. Our intention was to build an app to help translate the mishmash of files into structured data about the ad buys, ultimately letting voters sort the files by market, contract amount and candidate or political group (which isn’t possible on the FCC’s web site), and to do it with the help of volunteers.
In the end, Free the Files succeeded in large part because it leveraged data and community tools toward a single goal. We’ve compiled a bit of what we’ve learned about crowdsourcing and a few ideas on how news organizations can adapt a Free the Files model for their own projects.
The team who worked on Free the Files included Amanda Zamora, engagement editor; Justin Elliott, reporter; Scott Klein, news applications editor; Al Shaw, news applications developer, and Jeremy Merrill, also a news applications developer. And thanks to Daniel Victor and Blair Hickman for helping create the building blocks of the Free the Files community.
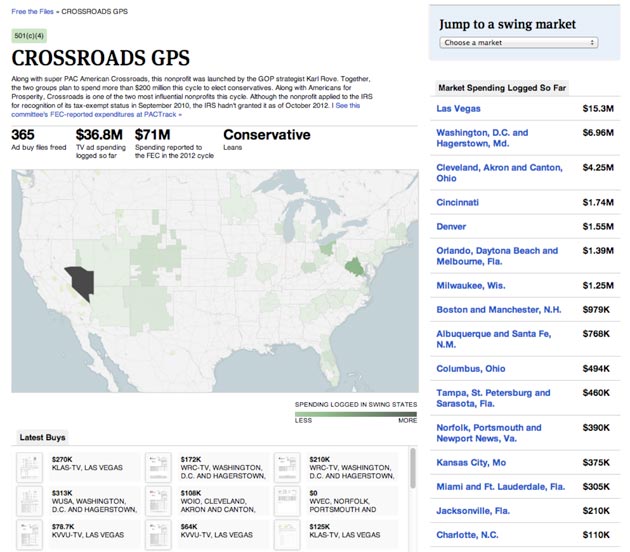
We started Free the Files as we do with any major data project — asking ourselves what story we wanted to tell (how dark money spending was impacting the election) and what information we had available to tell it (thousands of PDF files).
But turning the files into something reportable would require manual review of each document, a crowdsourcing challenge compounded by the fact that we had no idea exactly how many files we would be dealing with. Every day volunteers reviewed hundreds of files, and every day we downloaded hundreds more from the FCC web site. It was like starting a race without knowing when you’d hit the finish line.
So we narrowed the scope of our project to increase our chances of participation. We decided to review files in 33 swing markets, not all 50. We also limited the data elements we asked people to help us verify, paring down to the minimum necessary to tell our story.
While the documents offered many interesting details about each ad buy (target demographic, cost per TV spot, date and title of each spot, etc), we focused on four key pieces of data that would help us track spending: Who bought the ad, the agency placing the ad, the contract number and the amount of the ad buy. Could we have had people transcribe every possible piece of data? Sure. Could we have exhaustively digitized 11,000 files by election day? Probably not.
When a visitor arrives at Free the Files, one of the first things they see are project metrics: the number of files “freed” and the total ad spending logged by our volunteers. These were our success metrics, touted each day to keep the momentum going and spur new participation. If we didn’t know when (or if) we would complete the last file, we could certainly celebrate breaking another million in ad spending.
We also encouraged volunteers individually with a personalized progress report stripped across the top of the app for every logged-in user: “You have reviewed 700 files, here’s another from Cleveland, Ohio!”
In addition to these public figures, the ProPublica team tracked the number of volunteers and files processed each day (scraped from the FCC site, reviewed, freed and discarded). We also kept track of how accurate our volunteers were: In order for a file to be freed, at least two volunteers had to agree on each data point. Our analytics helped us track how many people it took to free a file (an average of 2.8), measure our pace, and estimate how many files we could expect to complete.
We saw participation spike after three key events: teaming up with the Huffington Post in four markets (Denver, Detroit, Miami, and Washington, D.C.); hosting a live document review session with the The News Outlet in Youngstown, Ohio; and creating an Election Day Challenge aimed at freeing all the remaining files in Las Vegas. These mini-challenges helped break a huge project into more achievable chunks and gave our crowd something to rally around.
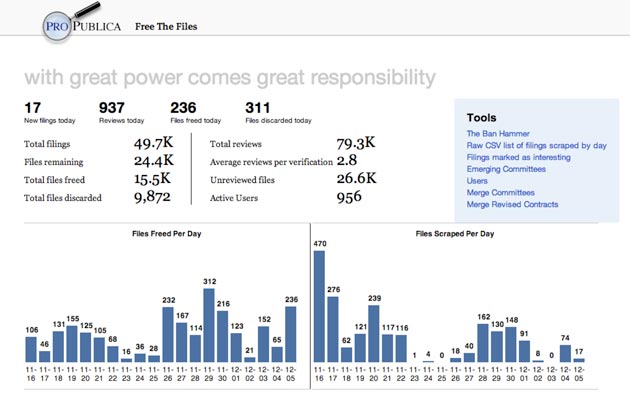
What we would have done differently: We weren’t sure exactly what reporting data we’d need until the project got underway, and ended up building some stuff along the way that we wished we’d had from the start. For instance, we launched with an internal daily stats email and a dashboard of key metrics to track our progress. But we ended up hand-compiling a spreadsheet of document review rates and ad data for each market so we could share weekly progress reports with our volunteers. Next time, in addition to having a dashboard with aggregate metrics, we would have started out with a simple way to share all of our progress data by day.
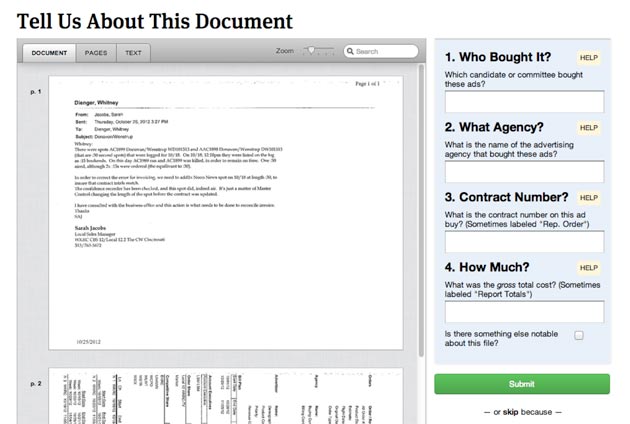
The success of Free the Files hinged in large part on the design of our app. The easier we made it for people to review and annotate documents, the higher the participation rate, the more data we could make available to everyone. Our maxim was to make the process of reviewing documents like eating a potato chip: “Once you start, you can’t stop.”
We also broke out of our normal article template and used a special design for our document review page, based on the design of our Message Machine app. The page is spared any extraneous links or bits of information that could distract a person from the immediate task. The only links are in a personal progress bar and “help” section that offers guidance on interpreting the documents. The result is an addictive, game-like experience that made it fun for people to participate.
We also ensured that volunteers could review documents with one click: a big green “give me a file!” button is featured at the top of the app and on the page for each ad market. We also created a widget that partners could easily embed on their websites to get their readers freeing files with one click.
What we would have done differently: We also might have personalized the “gimme” button to retrieve files from markets based on a volunteer’s location, as detected in their IP address or Facebook profile.
We leveraged social networking in three key ways to help build participation.
— We used a hashtag and customized Twitter sharing to help drive participation. Hashtags are a great way to unify conversation on Twitter around a project, and we used #FreeTheFiles for both project and personalized updates. We tweeted every progress report from ProPublica with #FreeTheFiles, but also built customized share buttons into the document review tool to enable volunteers to help us spread the word and tout their own participation. And Twitter was the leading source of traffic to the app.
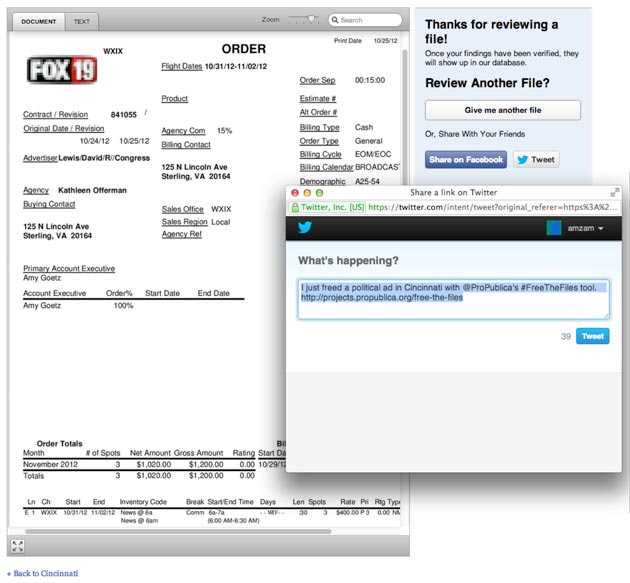
— We leveraged Facebook to help power a friendly leaderboard. We injected a little friendly competition into the project by tracking the top 10 volunteers leading document reviews each week and through the entire project. The leaderboard included the faces of volunteers who logged in through Facebook (nearly half of all active participants) and gravatars for everyone who logged in with email addresses.
Beyond spurring competition, the leaderboard helped us recognize and reward our top volunteers. The all-time top 10 earned t-shirts for their efforts, but more importantly, we contacted them to learn more about what drove each of them to participate. After reviewing more than 3,600 files, volunteer Sarita Nemerow Eisenstark noted that she was “amazed at the volume of money flowing. To see just a $$ figure on a chart or in an article doesn’t have the impact of turning page after page after page, many with hundreds of thousand of dollars flying out.”
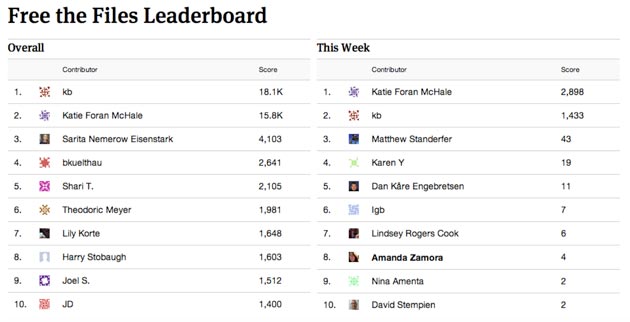
— We used Facebook groups to stay in touch with volunteers. In the end, the group became a practical home for our “super users,” who posted when they had questions about the ad filings and alerted us to bugs in the document review tool.
As a community manager, the group gave us a way to respond to volunteers directly without overwhelming our entire Facebook and Twitter audience. And the group proved helpful for our developers, too. Based on their feedback, we added two more buttons to the document review tool to help volunteers weed out extraneous documents.
The takeaway: Create a space to gather feedback from your volunteers and be responsive to their needs. Though our Facebook group was small, its dedicated members helped make the experience better for the hundreds of people who participated.
After 10 weeks, 16,000 files freed and up to $1 billion in ad contracts logged, we’re winding down Free the Files.
ProPublica’s goal was to illuminate dark money spending in the election. Our volunteers helped us do just that by creating a searchable, sortable dataset. Thanks to them, we were able to pair ad buyers in 33 markets with our PACTrack database, allowing readers to identify dark money groups and drill deeper into overall expenditures as reported to the Federal Elections Commission. And thanks in part to our readers’ efforts, we published story after story on dark money groups.
But despite all of this, we still can’t get an accurate count of the money spent. The FCC’s data is just too dirty. For example, TV stations can file multiple versions of a single contract with contradictory spending amounts — and multiple ad buys with the same contract number means radically different things to different stations. But the problem goes deeper. Different stations use wildly different contract page designs, structure deals in idiosyncratic ways, and even refer to candidates and groups differently.
By 2014, all broadcast TV stations will be required to post their political ad files online. But as long as they are allowed to post the kind of material they posted this year, the data will be virtually useless.
So we’re ending Free the Files 2012 with a challenge to the FCC for 2014: take the lead from our 1,000 volunteers and begin requiring stations to submit at least a subset of key data points as structured data when they submit their ad files to you online.
We built an app for that, it happened to work, and we’ll even share the code with you.




