Nieman Foundation at Harvard
Remember Flash?

The fate of so many Flash games and interactives, absent proper guardians, is part of a broader problem: how to rescue work painstakingly built on now-outdated formats from the dustbin of internet history.
It’s one The New York Times has been grappling with for its two decades of online content. The entire organization is moving from a previous version of the system that had been powering NYTimes.com to the latest framework. (For those following extremely closely, the stack was called NYT4 from 2006 to 2014 and NYT5 starting in 2014; the new system is called VI.) With these changes, article pages can get broken or shoehorned into a new page format in which important elements of the original piece disappear. The Times has recently started moving its published content — that’s everything from web pages to images to fonts to CSS files — from its own data centers to cloud services, spurring a concerted internal push to systematically un-break and preserve as many of its older pages as possible.
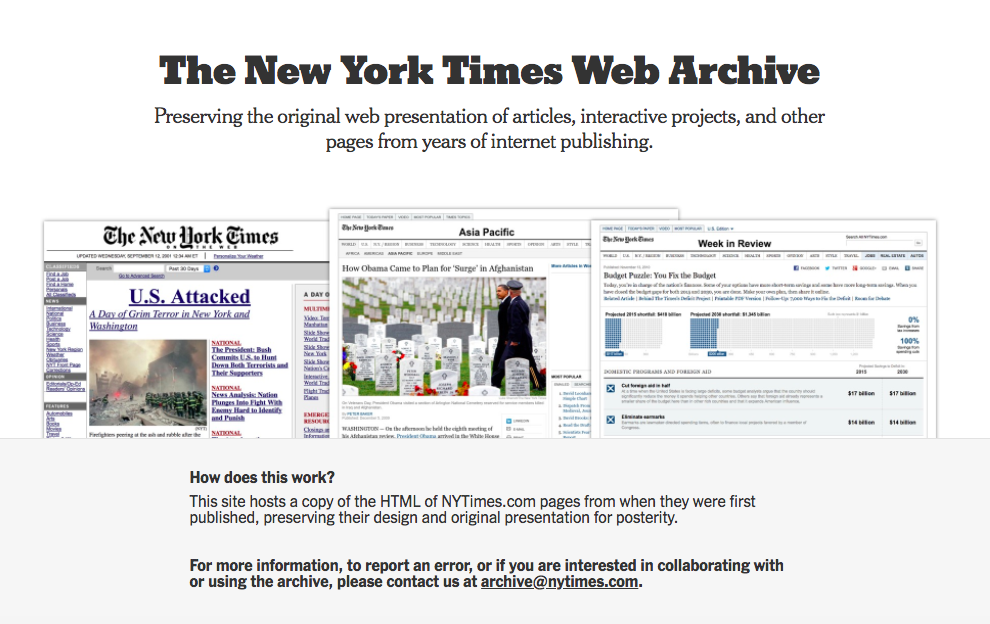
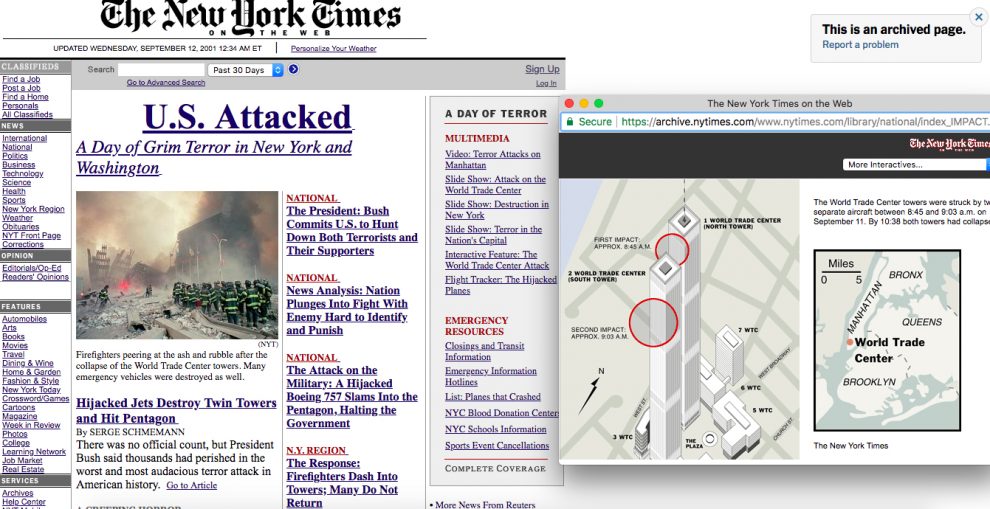
Readers can now see some public-facing fruits of that labor. The Times started directing some traffic to old stories to archive.nytimes.com in the past few months. If you go searching for the Times’ real-time coverage of the 9/11 attacks, for instance, you might get to the this archived page, where you’d see the page nearly exactly the way it appeared to site visitors on that day in time. (There aren’t live ads on these archived pages, mostly since the old ad technologies being used on those pages no longer work. Nor would you see modules like “Most Read” or “Most Emailed.”)
“When we started this effort last summer, it was exciting to have people involved who believed it was important to preserve the original presentation of things,” Eugene Wang, a senior product manager at the Times, said. Wang is part of a core team that works on the Times’s archiving efforts, which are part of a broader internal effort called Project Kondo (as in, life-organizing phenomenon Marie Kondo) to review old features and initiatives on the site — and then decide what to save and what to shut down. “There was one path we could’ve taken where we’d say: We have all these articles and can render them on our new platform and just be done with it. But we recognized there was value in having a representation of them when they were first published. The archive also serves as a picture of how tools of digital storytelling evolved.”
Here’s “Angry Birds, Farmville and Other Hyperaddictive ‘Stupid Games,’” a 2012 New York Times magazine story, as it appears on the site today.

Click on “see how this article appeared when it was originally published on NYTimes.com” and it’ll take you to the archive.nytimes.com version of the article, which has mostly replicated the original flash game that accompanied the story online in 2012:


“Because we were moving things from one domain another, from www.nytimes.com to archive.nytimes.com, some of them depended on assets existing on certain paths that wouldn’t be on those specific paths anymore. So we needed to figure out how to identify in an automated way these pages that were not maintained but being shown to readers,” Times software engineer Justin Heideman, who built internal tools to help create the online archives, said. “A lot of the things we discovered were already broken. These were things built 10 years ago, maybe more, that nobody had been maintaining for maybe 9.5 years. And when we do come across a thing that’s broken, it’s a bit of web archaeology to figure out why it’s broken, if it’s broken for any unique reason, or if there’s a whole class of pages that are broken that can be fixed as a class.”
The Times team first made sure to screenshot via Google Chrome and save to Google Cloud 740,000 articles that would at least be preserved in that way, should something go seriously wrong in the archiving process. I’ll let Heideman describe what he built to actually move pages into the official Times web archive. (He also described the technical process in depth at a talk last November at RJI’s Dodging the Memory Hole, if you’re interested in additional nitty gritty.)
For the archiving itself, we built a tool I called the ‘munger.’ It’s basically a big complicated find-and-replace engine in JavaScript, where we find references to servers that aren’t running, dynamic code blocks, old tags, and all kinds of other junk and strip it out or clean it up. The end result we get is tidied, clean HTML that we can share with the world and that has a more reliable set of dependencies. The munger runs with un-modified data we copied into Google Cloud Storage and outputs archival HTML into another GCS bucket, so we can re-run the pipeline again and again as we discover/fix bugs.
We also tried to update pages from HTTP to HTTPS, and to facilitate this we used the same tooling for screenshotting to analyze the pages in a real browser and see if they would throw mixed content errors (where an HTTPS page tries to load HTTP content), which could break a page. So our archive is a mix of HTTP and HTTPS pages. It is simply not practical for us to fix every page. We do this by injecting a bit of data about the page into the page itself, which lets a script we also inject figure out if it should be HTTPS or not, in addition to adding a visual header on the page letting visitors know that it’s an archived page.
“Some stuff just keeps working fine. For the most part, this is a thing that people rarely think about except when things go wrong. These stories are so dependent on code, on special designs, and everyone needs to be focused on their next stories, so there’s overall not much thought given to how old stuff works,” Albert Sun, assistant editor of news platforms at the Times, said. “When we make a transition to use the latest and greatest website system — one that gives us the latest ad framework, that plays well with the subscriber model, is nicely mobile-optimized — we can lose a lot of that original work. Given the amount of work and attention and care that’s gone into producing all of these pieces over the years, this seemed like a real shame.”
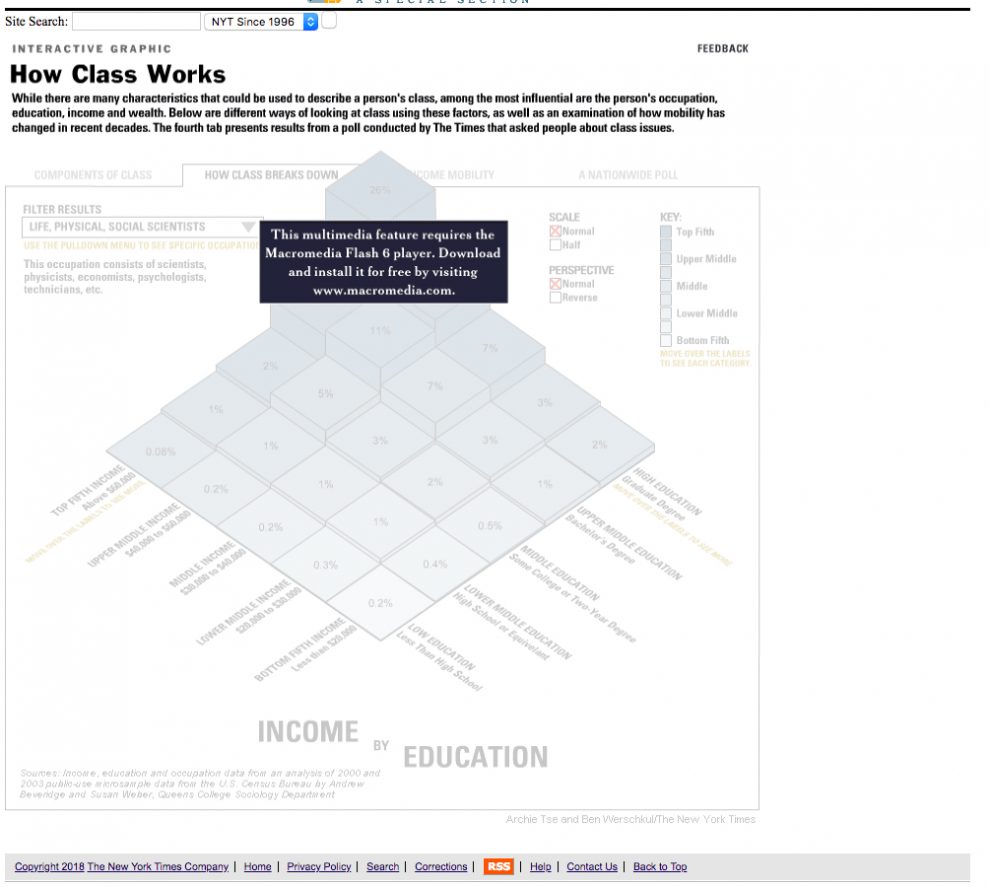
“There are some instances of old stories where, when we put them into the archive we were still getting a ton of reader interest on them, or it turned out a story ranked really strongly in search and people were upset their links stopped working,” Sun said. A 2005 David Leonhardt project around income and class in America, for instance, was being assigned as part of class reading. “A bunch of people actually wrote in to say: I can’t do my homework. That was a good reminder that people, over a decade later, still find value in that page.”
“For us, there are implications outside just our own pages to making sure things we served back then on a particular path, continue to be there forever. For instance, Google Search may have indexed one of our photographs of George Bush, and if we broke that image, people may lose that search, and we lose that referral traffic,” Heideman said. “We like to think of ourselves as the paper of record, but then it’s important that we actually keep those records.”
(Somewhere, Nicholson Baker is laughing — and here’s an archive.nytimes.com article page to prove it.)





{kind=link}