Nieman Foundation at Harvard

Often, when there’s talk about algorithms and journalism, the focus is on how to use algorithms to help publishers share content better and make more money. There’s the unending debate, for example, over Facebook’s News Feed algorithm and whose content they’re giving preference to. Or there are people like Chris Wiggins, recently interviewed by Fast Company, who uses his decade long career as a biology researcher and data scientist to advance the mission of The New York Times, from outside the newsroom.
But Nick Diakopoulos, a Tow Fellow at Columbia, wants to expand what journalists think about when they think about algorithms.

Diakopoulos doesn’t mean using algorithms to visualize data, though. He wants reporters to learn how to report on algorithms — to investigate them, to critique them — whether by interacting with the technology itself or by talking to the people who design them. Ultimately, writes Diakopoulos in his new white paper, “Algorithmic Accountability Reporting: On the Investigation of Black Boxes,” he wants algorithms to become a beat:
We’re living in a world now where algorithms adjudicate more and more consequential decisions in our lives. It’s not just search engines either; it’s everything from online review systems to educational evaluations, the operation of markets to how political campaigns are run, and even how social services like welfare and public safety are managed. Algorithms, driven by vast troves of data, are the new power brokers in society.
Investigating algorithms is Diakopoulos’s main focus at Tow. Over the summer, he did some research into Google’s auto-complete algorithm, ultimately publishing his findings at Slate.
Diakopoulos then became interested in how other journalists were getting to the core questions of algorithm building. Specifically, he wanted to know what processes they were using to figure out what goes into an algorithm, and what is supposed to come out. After looking at examples of investigations into algorithms from ProPublica, The Wall Street Journal, The Atlantic, The Daily Beast and more, Diakopoulos wrote up his observations for The Atlantic. The Tow white paper, published last month, is an expansion of those thoughts and inspired a panel at the NICAR conference held last week in Baltimore, where Diakopoulos shared the stage with Frank Pasquale, The Wall Street Journal’s Jeremy Singer-Vine, and The New York Times’ Chase Davis.
“I started developing the theory a little bit more and thinking about: What is it about algorithms that’s uncomfortable for us?” Diakopoulos told me. “Algorithmic power is about autonomous decision making. What are the atomic units of decisions that algorithms make?”
It’s inherently challenging for people to be critical of the decisions that machines make. “There’s a general tendency for people to be trusting of technology,” says Diakopoulos. “It’s called automation bias. People tend to trust technology rather than not trust technology.”
Automation bias is what causes us to follow wrong directions from a GPS, even if the route is familiar. It’s also, some say, what tragically caused Air France Flight 447 to crash into the Atlantic in 2009.
In the same way, Diakopoulos argues, we believe that Match.com’s algorithms want us to find true love, that Yelp wants to find us the best restaurants, and that Netflix wants to show us the most entertaining movies. Diakopoulos argues that it’s a journalist’s responsibility to determine whether that’s true or if it’s just what those companies want us to believe. (Remember: Media companies use algorithms too, which means “some of the same issues with transparency arise” there as well.)
“Because [algorithms] are products of human development, there may be things that we can learn about them by talking to the people who built them,” says Diakopoulos. In the paper, he writes that “talking to a system’s designers can uncover useful information: design decisions, descriptions of the objectives, constraints, and business rules embedded in the system, major changes that have happened over time, as well as implementation details that might be relevant.”
But more often than not, interviewing engineers is not an option — even government algorithms are protected by a FOIA trade secret exception that shields third-party source code. There is at least one known instance of source code being successfully accessed via FOIA:
@ceodonovan @ndiakopoulos @mattwaite Here's an example from @morisy. Code: https://t.co/cbpGMrT6K2 Explanation: https://t.co/8brKZamABg
— Jeremy Bowers (@jeremybowers) March 3, 2014
But ultimately, Davis said, reporters shouldn’t expect to get much information out of the government. “Reporting on these things and getting information out of institutions is similarly black-box. These things are protected trade secrets. FOIAing source code, if it was put together by a government contractor, or even maybe the government itself? Good luck. Probably not going to happen.”
At NICAR, Pasquale told journalists to pay attention as laws about accessing technological information develop. “I would recommend that everyone in this audience, to the extent that journalists can be advocates, that we closely follow the workshops on data brokering and algorithm decision making that the FTC is putting on,” he said.
If you can’t talk to the people that wrote the algorithm, what next? “When corporations or governments are not legally or otherwise incentivized to disclose information about their algorithms, we might consider a different, more adversarial approach,” Diakopoulos writes.
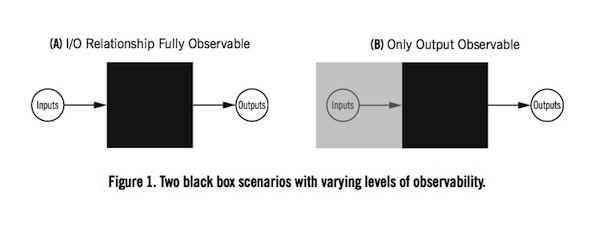
That approach is reverse engineering, which basically means putting things into an algorithm, observing what comes out, and using that information to make some guesses about what happened in between — the zone of the black box. It’s an idea supported by a basic principle of engineering: Taking something apart is a good way of learning how it works.

When The Wall Street Journal and Singer-Vine wanted to find out whether or not online vendors like Staples were selling items for different prices based on who the shopper was, they also used reverse engineering. The paper built proxy servers and developed user profiles to create “painstakingly simulated inputs” which they compared to the price outputs. What they found was that stores seemed to be varying their prices based on where customers were located geographically.
“If you think about a cell in your body, a biologist is reverse-engineering that cell to understand how it works. They’re poking and prodding it, and seeing how it responds, and trying to correlate those responses to come up with some theory for how that cell works,” Diakopoulos says. Citing Paul Rosenbloom’s book On Computing: The Fourth Great Scientific Domain, Diakopoulos argues that some of our algorithmic systems have become so large, they’re more usefully thought of as resembling organisms rather than machines. “The only way to really understand them is by applying the same techniques that we would apply to nature: We study them with a scientific method. We poke and prod them and see how they respond.”
Singer-Vine spoke to the same issue at NICAR. As algorithmic systems grow and grow, finding a language to explain what you’ve learned without using misleading metaphors or implying causation where it doesn’t exist is only going to get more complex. “To translate your findings is only going to get harder,” he says. “If an algorithm is so complex that nobody can explain why one thing happened because of another, maybe that’s a story in and of itself.”
Of course, there are challenges and risks to using reverse engineering. Ultimately, while it can sketch a story, it can’t tell you exactly why or how engineers wrote an algorithm. “Just because you found a correlation between two variables in reverse engineering, doesn’t mean there was some programmer who wrote that algorithm who decided that it should be that way. It might have been an accident. There may have been some complexity in the algorithm that was unforeseen. You can’t make the inference that this was done on purpose,” says Diakopoulos.
Nick Seaver, who studies algorithmic cultural phenomena at UC Irvine, says that while Diakopoulos’s examples of journalistic reverse engineering are intriguing, he’s ultimately more of a pessimist regarding reverse engineering’s potential as a reporting tool. In an email, Seaver writes:
The systems we’re talking about are complicated and change very rapidly. Words that are not blocked today may be blocked tomorrow, and if we’re dealing with machine learning algorithms, they might be blocked for reasons that even their own engineers don’t immediately understand. These systems are also constantly under A/B testing, so there is more than one system in play at any given moment. […] As a result, on major websites, there can be literally millions of different permutations in use at any given moment. So, reverse engineering, while it is miles ahead of what many journalists do when it comes to reporting on algorithms, is up against some significant challenges.
At NICAR, Pasquale brought up another example, Nathan Newman’s 2011 investigation into potential racial implications for the algorithm that determines the personalization of Google ads. While Newman’s findings were interesting, Pasquale says, “Google says you can’t understand their methodology based on personalization.” Their full rejection of his claims were:
This post relies on flawed methodology to draw a wildly inaccurate conclusion. If Mr. Newman had contacted us before publishing it, we would have told him the facts: we do not select ads based on sensitive information, including ethnic inferences from names.
But Diakopoulos sees a future where the tactics of reverse engineering and the tools of reporting are blended into a unified technique for investigating algorithms. “You see how far you can get — see if you can find something surprising in terms of how that algorithm is working. Then, you turn around and try to leverage that into an interview of some kind. At that point, the corporation has an incentive to come out and talk to you about it,” he says. “If you can combine that with observation of the system through reverse engineering, then I think through that synthesis you get a deeper understanding of the overall system.”
As journalists charge after this potential new trend in data journalism, however, it’s worthwhile to remember this note from Diakopoulos on the consequences of revealing too much about the algorithms we rely on.
He writes: “Gaming and manipulation are real issues that can undermine the efficacy of a system. Goodhart’s law, named after the banker Charles Goodhart who originated it, reminds us that once people come to know and focus on a particular metric it becomes ineffective: ‘When a measure becomes a target, it ceases to be a good measure.'”
During the NICAR panel, Singer-Vine raised the same issue, pointing out that making the mechanics of algorithms publicly available also makes them more “gameable.” (Ask all the SEO consultants for whom understanding Google’s search algorithms is the holy grail.) But Pasquale pushed back on this concern, arguing, “Maybe we should try to expose as much as possible, so that the people involved will build more robust classifiers.”
Diakopoulos’ plans to move forward with algorithm investigations are primarily academic. Although the paper concludes it’s too soon to consider how best to integrate reverse engineering into j-school curricula, Diakopoulos says it’s a major interest area. “I think if we taught a joint course between journalism and computer science, we would learn a lot in the process,” he says.
Primarily, he’s interested in finding more examples of journalists using reverse engineering in their work — not that he has any shortage of his own ideas. Given the opportunity, Diakopoulos says he’d be interested in investigating surge pricing algorithms at companies like Uber, exploring dating site algorithms, looking for bias in selection of immigrants for deportation, and more. He’s also had conversations with Columbia’s The New York World about collaborating on an investigation of New York municipal algorithms.
For journalists who want to be thinking more critically — and finding more stories — about the machines we rely on, Diakopoulos offered some advice on newsworthiness. “Does the algorithm break the expectations we have?” he asked. “Does it break some social norm which makes us uncomfortable?”
Visualization of a Toledo 65 algorithm by Juan Manuel de J. used under a Creative Commons license.




