Nieman Foundation at Harvard

Starting this week, however, most Times stories published since 2004 are now available in the newer article format, and it’s taking steps to bring the rest of its archives into the new system.
In a blog post published on the Times’ site, software engineer Sofia van Valkenburg and Evan Sandhaus, the Times’ director for search, archives and semantics, wrote that “engineering and resource challenges prevented us from migrating previously published articles into this new design.”
As so often happens, the seemingly ordinary task of content migration quickly ballooned into a complex project involving a number of technical challenges. Turns out, converting the approximately 14 million articles published between 1851–2006 into a format compatible with our current CMS and reader experiences was not so straightforward.
The Times’ archives were in XML format and it needed to convert the stories into JSON in order for it to be compatible with its CMS. This process worked smoothly for the paper’s archives from 1851 through 1980. For more recent coverage, however, there were stories missing from the archive, which only included the final print edition of stories. Staffers found that in just 2004, there were more than 60,000 stories that were published online but not included in the XML archive. As a result, the Times scoured other databases, sitemaps, and analytics to try and capture as many stories as it could in raw HTML format that weren’t in the XML database.
After locating the missing stories, the Times realized that there were a number of duplicates. Using a technique called shingling, which it initially used for its TimesMachine archive, the paper was able to eliminate many of the duplicates. From the 60,000 articles from 2004 that weren’t initially found, it was able to match more than 70 percent of missing stories.
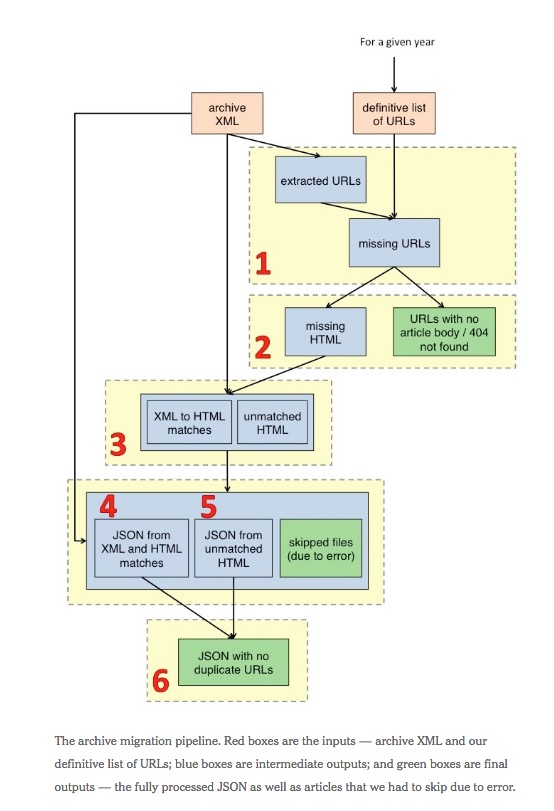
Once it assembled a more complete list of stories, the Times undertook a six-step process to “derive structured data from raw HTML for items not present in our archive XML”:
1. Given the definitive list of URLs and archive XML for a given year, determine which URLs are missing from the XML.
2.Obtain raw HTML of the missing articles.
3.Compare archive XML and raw HTML to find duplicate data and output the “matches” between XML and HTML content.
4. Re-process the archive XML and convert into JSON for the CMS, taking into account extra metadata from corresponding HTML found in step 3.
5. Scrape and process the HTML that did not correspond to any XML from step 3 and convert into JSON for the CMS.
6. Combine the output from steps 4 + 5 to remove any duplicate URLs.
As part of this process, the Times also improved the SEO on old stories and made them easier to find:
For example, on Feb. 12, 2004, the article “San Francisco City Officials Perform Gay Marriages” appeared under a URL ending with “12CND-FRIS.html.”. Realizing we could provide a much more informative link, we derived a new URL from the headline. Now this article is referenced by a URL ending with “san-francisco-city-officials-perform-gay-marriages.html,” a far more intuitive scheme.
The full post, with more technical details, is available here.



