Nieman Foundation at Harvard

As part of MakerWeek 2023, The New York Times’ annual hackathon, iOS and Android mobile engineers explored the ability to write in The New York Times Crosswords app on each respective platform. As an Android engineer who participated in the experiment, I’m excited to share my platform specific experience implementing on-device ML onto the Android Crosswords app.
(Note: This exploration is for a future feature which hasn’t been released yet.)

The New York Times Crossword has a custom software keyboard built into the app. When a user types a letter on the keyboard, it appears in that square.
To allow for handwriting, the first thing we needed to do was ensure that the user could actually enter text manually, via a stylus or their finger. We took each crossword square on both the Mini and the Daily and transformed it into a custom component we called SketchBox. This component captures each stroke made by the user’s finger or stylus as they write and is specially designed to listen for touch and drag events to display drawn letter strokes. After our SketchBox captured the resultant letter pixels from the canvas, we could then send the data to the machine-learning algorithm of our choice.
Before we get to the actual handwriting detection, we need to address a subtle but important point.

As a user writes on the SketchBox, they frequently lift their finger or stylus off of the canvas, especially to complete letters like K, A, H, etc. That means we need to determine when, exactly, a user was done writing, between each stroke. For example, if they draw the stem of a “K,” trying to detect the letter as soon as they lift their writing utensil, it could be misinterpreted as an “I.”
So how long do we wait between strokes? For our initial implementation, we introduced the concept of a mutex-like input locking system. Between each stroke, we experimented with values around 500 to 1000 milliseconds depending on certain conditions. We didn’t want to wait too long before unlocking the stylus — otherwise the user input experience would seem degraded and choppy.
This is one of the many complexities we had to consider as we designed the writing mechanic, and it’s something open for refinement in the future.
Before exploring conversion of images into text, we had to consider our input: letters from various devices with different screen sizes and resolutions.
An essential pre-processing step included getting the simplest form of the data that the algorithm needs for accurate learning. In the case of image data, this means getting rid of non-essential noise, and “frivolous geometry.” We downscaled and binarized the letter data, and then converted raw input letters of 128×128 pixels to efficient, simplified, and much smaller 28×28 images.

An image next to a black/white binarized version of it created to reduce unnecessary detail for easier character detection.
Once we did that, we could finally begin to discuss how to translate the rasterized canvas image data into an actual character that our crossword app can understand.
Handwriting recognition is a classic machine learning challenge within Optical Character Recognition (OCR). It has seen substantial advancements over the years, notably with Yann LeCun’s 1998 LeNet-5 architecture, which significantly improved digit recognition on the Modified National Institute of Standards and Technology (MNIST) dataset. The MNIST dataset contains thousands of variations of the digits 1–9, and is the de facto standard database for digit recognition.

A snapshot of several digits from the MNIST data set.
The system we were trying to build looks like this high-level architecture diagram:

The machine learning algorithm we chose was intended to provide the best separation of character data into recognition clusters, as idealized below. That way. it would be easy for our system to determine if the user wanted, for example, to enter an “A” or a “C.” We explored several other options, which I won’t go into detail about here, before settling on the use of a deep convolutional neural network (or Deep-CNN) architecture, which proved up to the task.
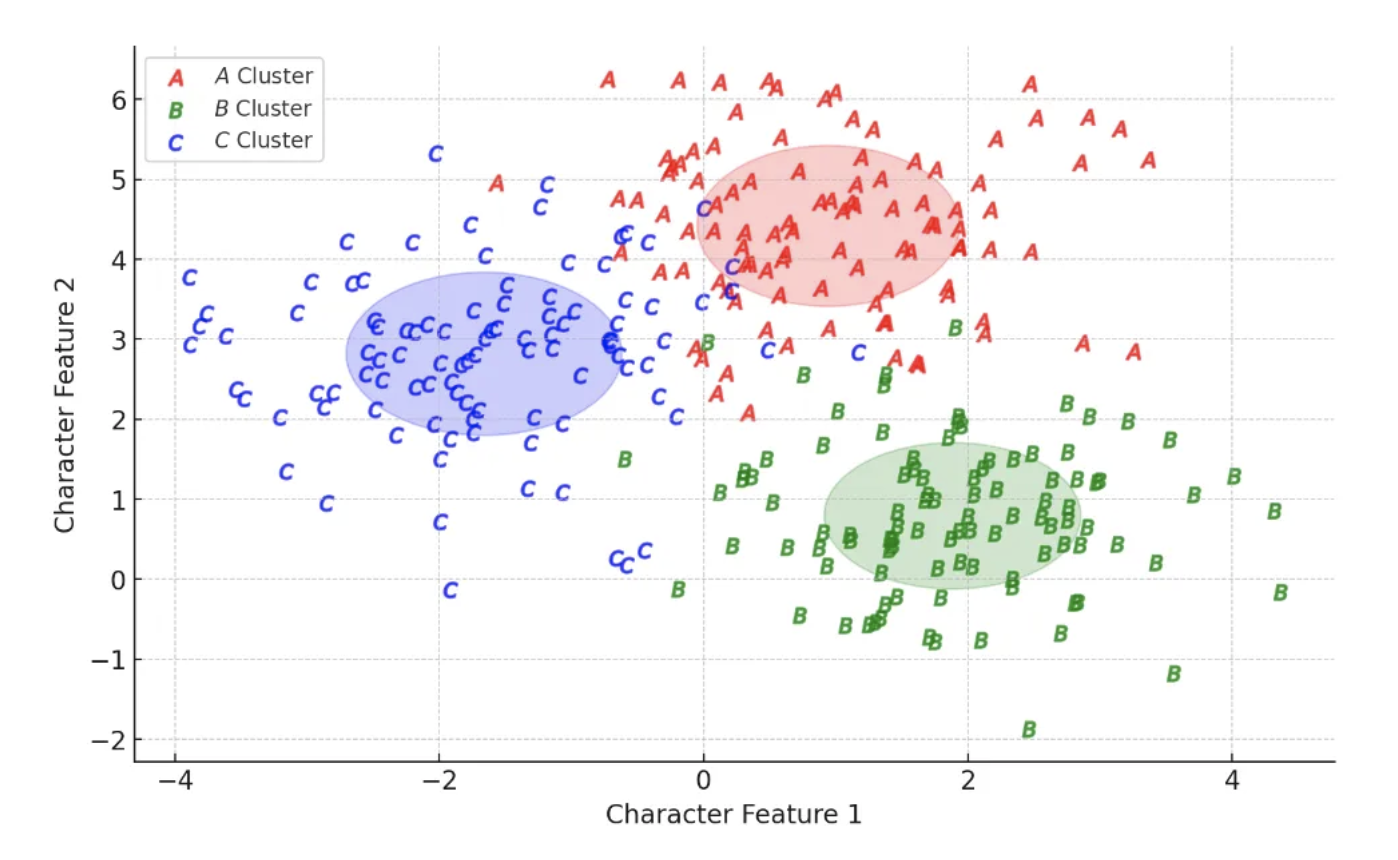
The Deep-CNN is the cornerstone of any legitimate modern-day image-based machine-learning system. It’s a special kind of neural network that examines sections of image data and, using its learning mechanic, intelligently finds important features that help identify and classify images.

In the example presented above, the neural network takes in an input image of a bird and detects structures that correspond to different qualitative elements of the bird. It can detect the portions of the image that correspond to feathers, eyes, edges of the beak, internal beak geometry, and a whole host of traits that a person would have difficulty designing an algorithm from scratch to do.
Using the most important features, it can then determine if it’s looking at a bird, and if so, what kind of bird it is. Provided the network is trained properly, we can even determine things like what direction the bird is flying in or looking toward. We apply the same principle to letters that a user inputs into our crossword app.
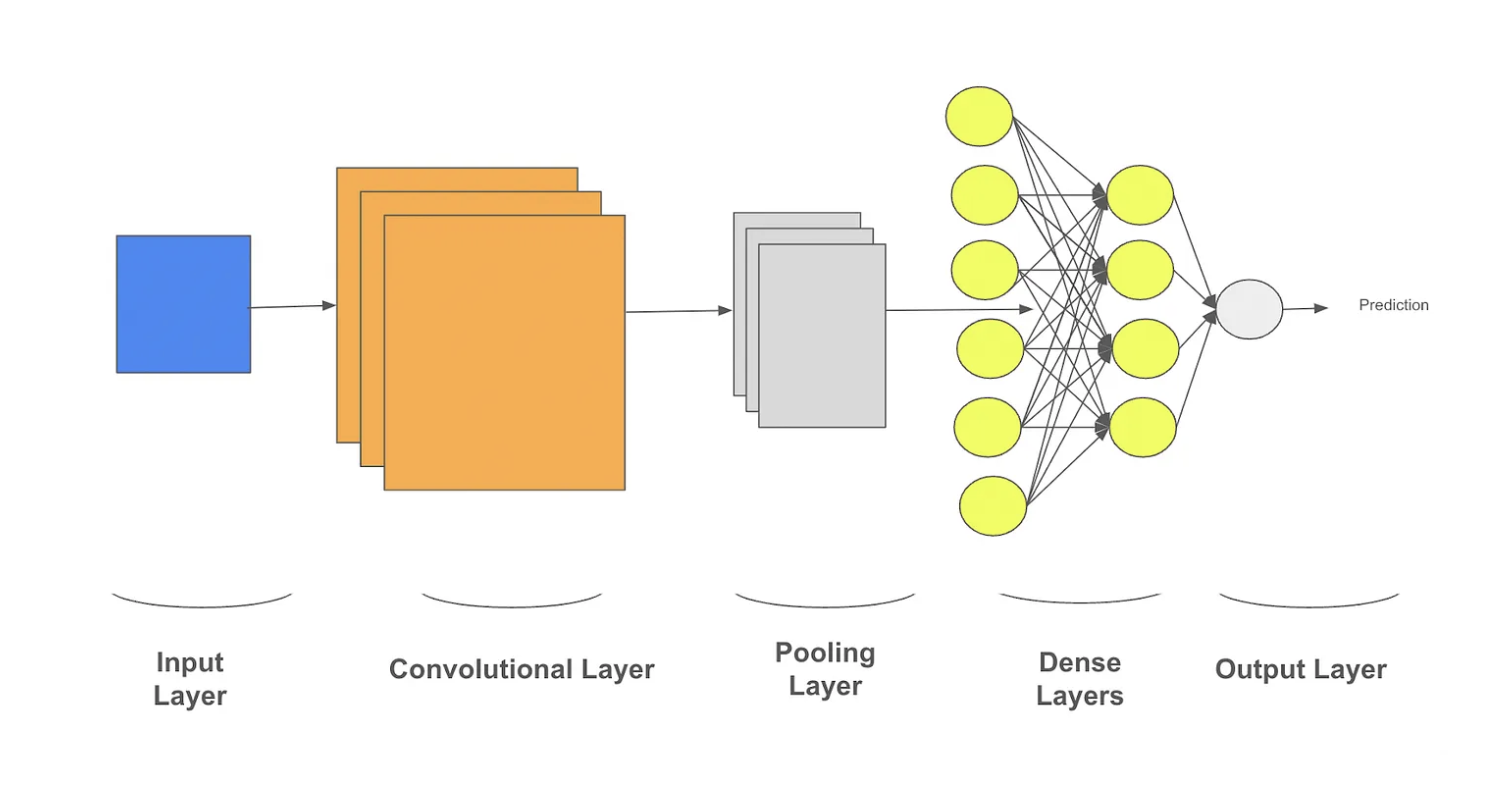
The basic CNN is a combination of the following elemental layers. By intelligently mixing and matching these structures with the proper parameters, there’s very little imagewise that we can’t detect:
In addition to building the model, we also had to find a way to deliver it to devices. We chose to use TensorFlow Lite, a mobile framework used to install Python-compiled ML models into an Android or iOS device.

The TensorFlow Lite framework for on-device model ingestion.
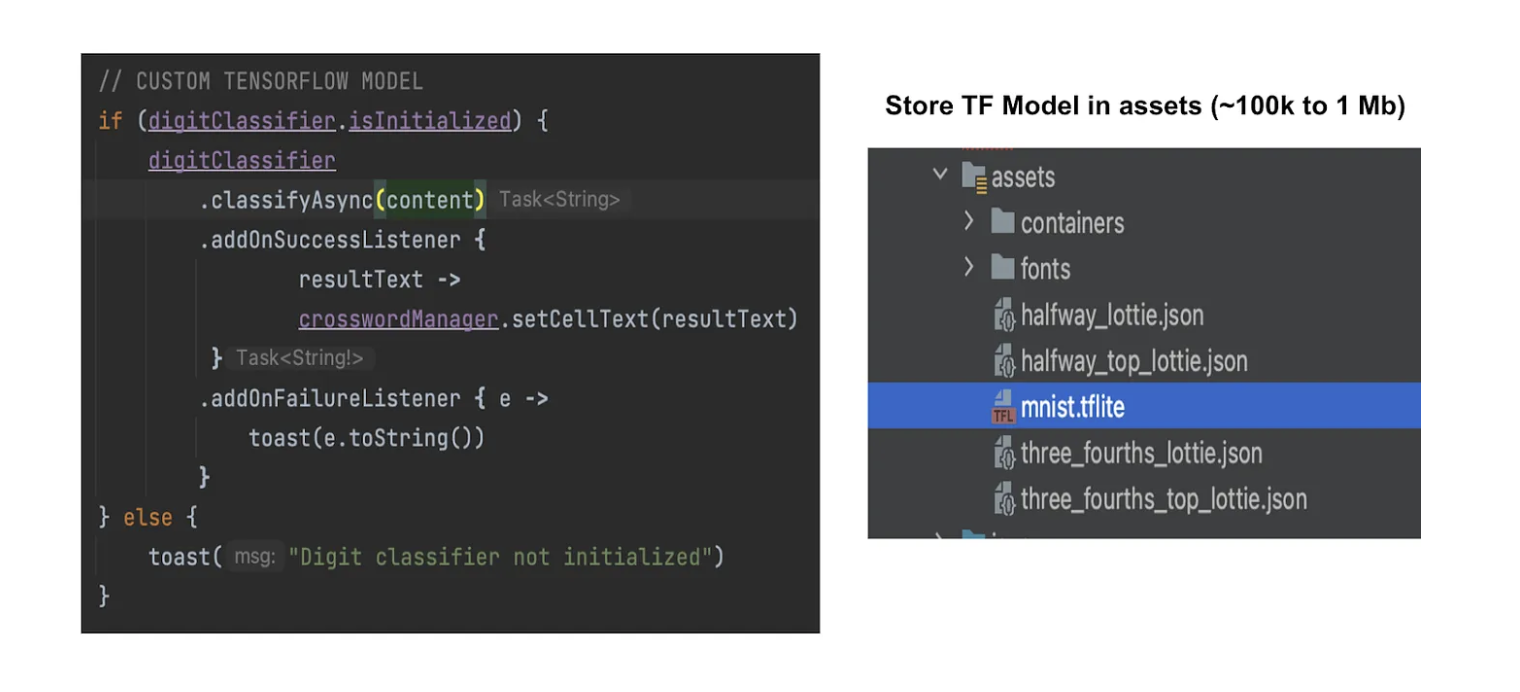
Once we were satisfied with our model, we compiled it to a .tflite file and baked it into our application, then built a shunt for listening to letter-writing events coming from the crossword squares. We iterated several times through different models and different configurations until we were satisfied with the final result, which turned into a trained file of only 100K or so — perfect for a mobile application, where space considerations are important.
Before approaching the problem of full-blown letter recognition, we decided to start simple and tackle the well-studied and foundational problem of numerical digit recognition. The core section of code below provides the basic CNN setup we implemented:

Despite abundant training data obtained from the MNIST, our recognition results were poor. We ascertained the training data was “too perfect.” All the digits were only minor variations of each other, and most were in the center of the box. This is not how people enter data into a crossword square. People have different handwriting styles and ways of tilting and placing the characters in the squares off center.
To solve this, we needed to employ a well known machine learning technique called data augmentation. Data augmentation generates off-center and distorted versions of our training data, bypassing the need for manual adjustments and skewing. This allowed for many variations of our initial data set, including significantly off-centered versions of our characters.

The image to the left shows the original digits, without much variation. To the right are the skewed, stretched, and off-center digits created via data augmentation.
With data augmentation, we expanded the size of our dataset from thousands to more than 1 million samples with off-center minor shifts, rotations, and scaling — also called affine transformations.
As you can see, the digit recognition has improved significantly on the real crossword — a milestone in our work!

Now that we’d solved digits, the next step was to solve letters, both lowercase and uppercase. Instead of ten digits, we were now dealing with 26 lowercase letters, 26 uppercase letters, and ten digits — 62 characters in all.
We can use the EMNIST dataset (source) — an expanded version of the MNIST set that includes both letters and digits and even punctuation — to help train the model better.
However, even with the enhanced dataset, the digit-specific model wasn’t enough for our needs. That’s not surprising; while the digit recognition model was powerful, it was surely not “intelligent” enough for the greatly expanded variation in character structure introduced by looking at letters.
To increase the power of our model, we added much more depth to our network in the form of several additional layers. We also employed stratified k-fold cross-validation to diversify our training by using randomized subsets of our augmented training/validation data.
To ensure that our layers were optimally designed, we employed a randomized parametric search along with enhanced statistical testing, which allowed us to find the optimal hyperparameters for our model. This proved to be an enhancement from our previous strategy of guessing the right parameters.
In testing, we reached an average validation accuracy of about 91% on the augmented EMNIST dataset. That gave us faith that our model would work.
And finally — success!

After a long journey exploring the landscape of ML model building, we finally arrived at a working crossword model — which was exciting. Even though we attained stellar results, there is still much work to do for the complete crossword experience, including dealing with partial letters and letters that are spaced at irregular intervals.
Implementing handwriting recognition on the Android crossword app was an exciting adventure, even in an experimental context. Aside from handwriting, there’s also potential for interactive features like “scribble-to-erase” detection, in-app self-training mechanisms, and a whole host of other doors that on-device ML in the Games app can open.
Having the opportunity to experiment with new techniques and amplifications to our existing products is a core part of why working at the Times as an engineer is so unique and so worth it. We hope one day to turn this into a feature that amplifies the Games experience for our current users and attracts new subscribers.
Shafik Quoraishee is a senior Android engineer on the Games team at The New York Times. This article originally appeared on NYT Open and is © 2024 The New York Times Company.




