Nieman Foundation at Harvard
Ed. note: Here at Nieman Lab, we’re long-time fans of the work being done at First Draft, which is working to protect communities around the world from harmful information (sign up for its daily and weekly briefings). We’re happy to share some First Draft stories with Lab readers. This is the first in a two-part series on explaining the role of AI in online content.
When an astonishingly realistic deepfake of Tom Cruise spread across the internet in March, many people were quite rightly shocked. Its pinpoint realism suggested artificial intelligence had leapt forward several years.
But one important feature was easily missed. By using the social media handle “deeptomcruise,” the creator was transparent about the fact it was a deepfake.
In a future full of media manipulated by artificial intelligence, we will need methods like this to indicate what is real and what has been faked with AI.1
And this won’t just be a question of ethics. The EU may require that users be told when AI has generated or manipulated something they are viewing.
How should we label AI media in ways that people understand? And how might it backfire?
To start making sense of this phenomenon, we’ve conducted a landscape review of how AI media is currently being labeled. It draws on our previous research on labels, and the insights of many experts in this field, focusing on any media that is generated or manipulated by automated technologies, especially through the use of AI.
In this report, we explore emergent tactics and offer a vocabulary for anyone who wants to label the role AI has played in their creation. In part two, we’ll reflect on the questions, tensions, and dilemmas they raise.
We use “labels” to refer to any verbal or iconographic item superimposed over content to indicate that it has been manipulated or generated by AI.
 Promo watermarks. Watermarks are icons or filters that visually cover content to advertise or cite the tool used to create it. They are also often automatically applied by commercial AI manipulation tools, such as impressions.app, as a means of promotion. This offers insight into the fact that the media was edited and a specific tool used to do so. (At right: Example of a promo watermark applied by Impressions.app; source: TikTok.)
Promo watermarks. Watermarks are icons or filters that visually cover content to advertise or cite the tool used to create it. They are also often automatically applied by commercial AI manipulation tools, such as impressions.app, as a means of promotion. This offers insight into the fact that the media was edited and a specific tool used to do so. (At right: Example of a promo watermark applied by Impressions.app; source: TikTok.)
While their effectiveness for different users may vary depending on the language and design, these labels have one simple advantage: If someone saves or screenshots an image or video and recirculates it out of its original context, the watermark travels with it. The more it covers the image or video, the harder it is to remove through editing techniques such as cropping or blurring.
Indeed, this technique has been used by stock image services, such as Shutterstock, for years to prevent the use of images without proper crediting or citation. However, editing out a watermark is certainly not impossible, a limitation that may be countered with stronger media authentication infrastructure, as we will discuss.
Filter tags. Filter tags are labels applied by an app to indicate when one of its filters has been used.
Filter tags have become a familiar convention on TikTok, Snapchat and Instagram, and have a specific advantage over other kinds of labels in that they are interactive. If you click on a filter tag, you can use it, giving you a practical understanding of what the filter does. It’s also possible to see other videos that have used the filter. These are distinguished from promotional labels because they are applied consistently and interactively within a particular platform. Here’s an example of a “Neon Shadow” filter tag, from TikTok.

The disadvantage is that they are not hard-coded onto the media, meaning that if you download a filtered video from TikTok, the tag will be lost. Additionally, the names of the filters tend to offer little insight into the nature and extent of the manipulation itself.
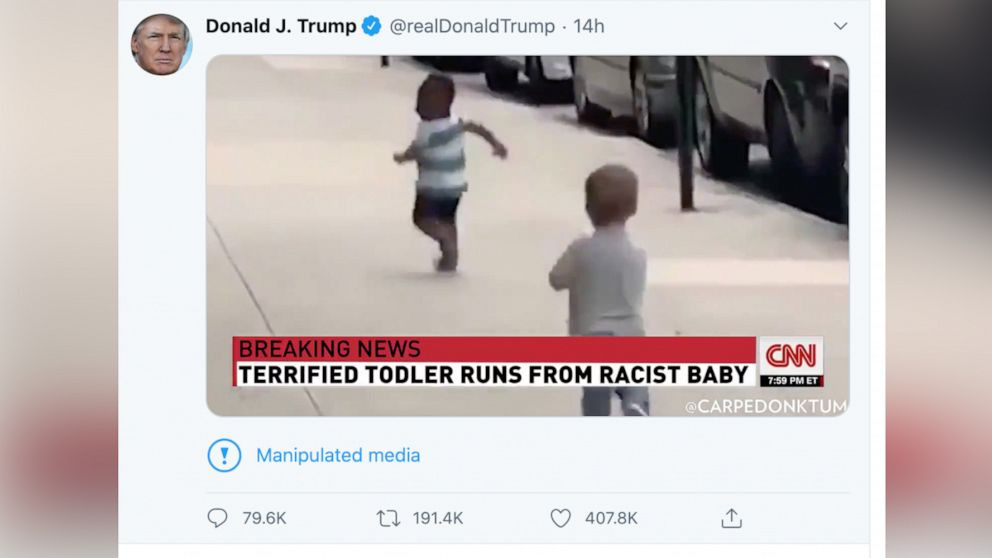
Platform warnings. Twitter’s synthetic and manipulated media policy outlines the conditions for applying warning labels on Tweets, using the same space as the platform’s fact check labels. While not covering the video or images, the placement of the warning in the middle of the post makes it visible simultaneously with the media. As with the filter tags, they are easily removed when the video is downloaded or recorded.
Here’s an example of Twitter’s manipulated media warning, applied to a cheapfake (we have not yet seen an example of its use on AI content).
 Non-platform warnings. Non-platform warning labels describe how third parties, such as journalists and fact checkers, cover media to add an explanation or context. This may be in the form of debunking a claim, or simply a label to describe provenance or note manipulation. At right, an example of a warning label from the News Literacy Project.
Non-platform warnings. Non-platform warning labels describe how third parties, such as journalists and fact checkers, cover media to add an explanation or context. This may be in the form of debunking a claim, or simply a label to describe provenance or note manipulation. At right, an example of a warning label from the News Literacy Project.
One example is the use of overlays that cover misinformed or manipulated content to prevent their recirculation when featured in news stories. This can be an effective technique in journalism. First Draft will be publishing guidance as part of this series on signposting online content, with recommendations for journalists on how to design overlays to reduce the amplification of misinformation.
We use “metadata” to refer to any description that is manually added to information that accompanies the content.
Title and caption. The title and description of a post provide a space to offer detail on the role of AI. In certain online contexts, they can be highly visible ways of alerting audiences. “The Deepfake Queen,” a video by Channel 4 News, alerts audiences to the use of deepfake technology in the title.
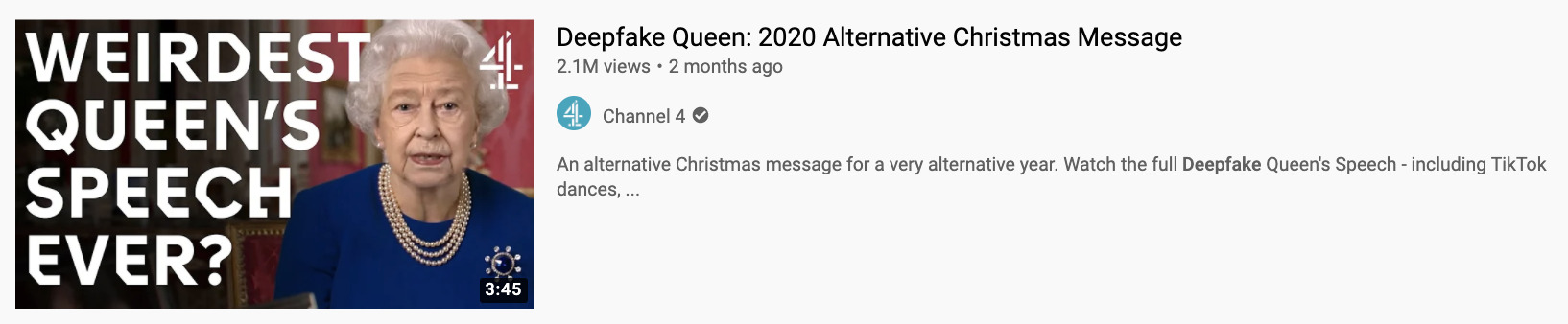
However, titles rarely have much space for detailing the role of AI, especially when needing to also describe something about the media’s content. What’s more, titles and descriptions often do not travel with the media, and the visibility of this metadata changes substantially depending on the platform and screen size.
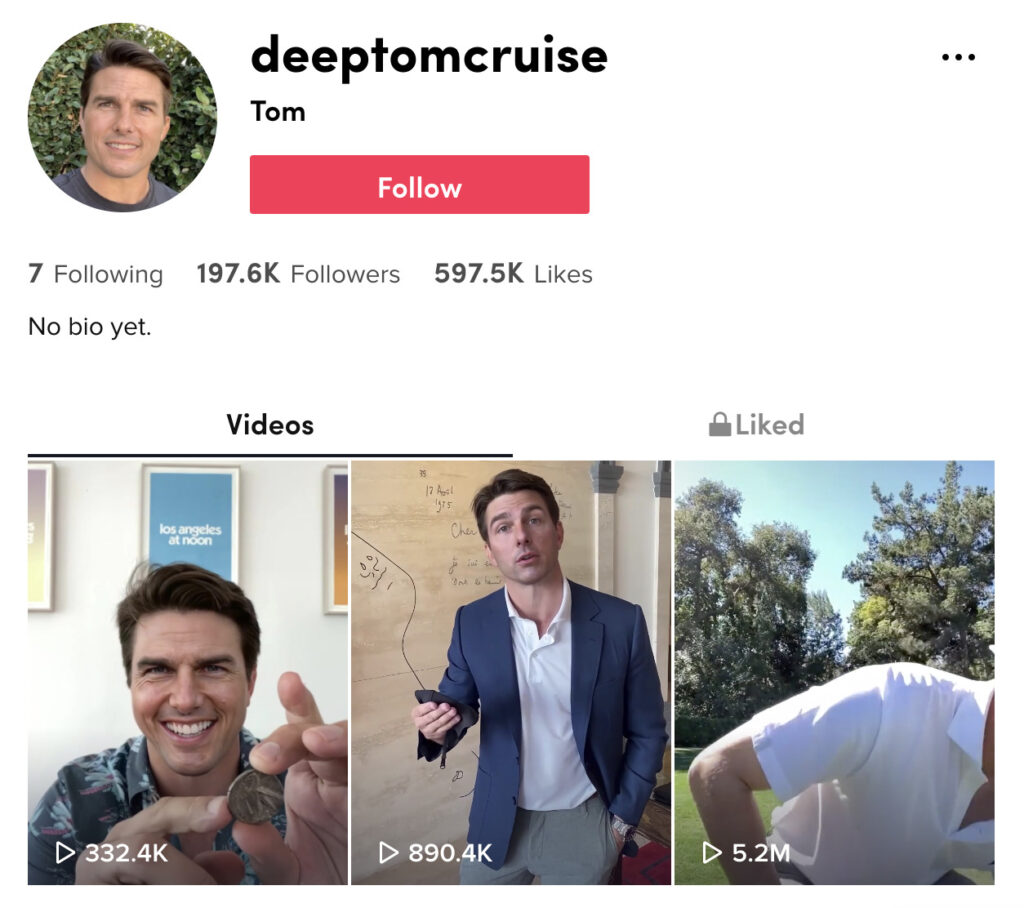
Profile information. Profile information, such as username and bio, can provide an indication or explanation of the synthetic nature of the account’s content. For example, the “deeptomcruise” TikTok account name provides an indication that the account contains deepfake Tom Cruise videos, for those aware of this usage of the term “deep” as terminology for AI-generated media. Here’s the Instagram profile of the virtual influencer @lilmiquela.
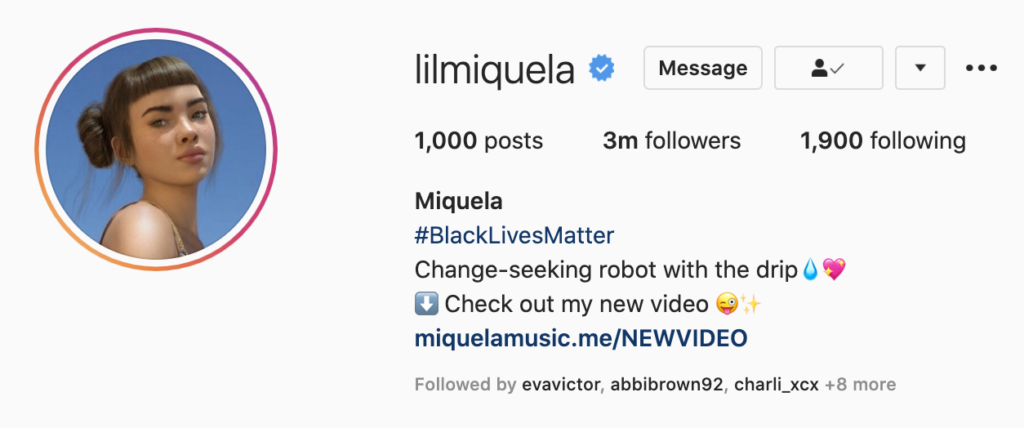
However, this can result in a single explanation for every post on that account, when each one may have used slightly different techniques. On most platforms you also have to click through to the profile page to see bio information, and so this may easily be missed. And because these details are added voluntarily by account creators for various reasons, they may be subtle or satirical in a way that is not widely understood.
Byline. A byline can attribute authorship to AI. It is similar to the username on an account, but it is worth distinguishing because a byline carries significant weight in journalism. An example outside the journalism context could include a signature on a painting — fine art’s equivalent of a byline. An example from a controversial Guardian article is below.
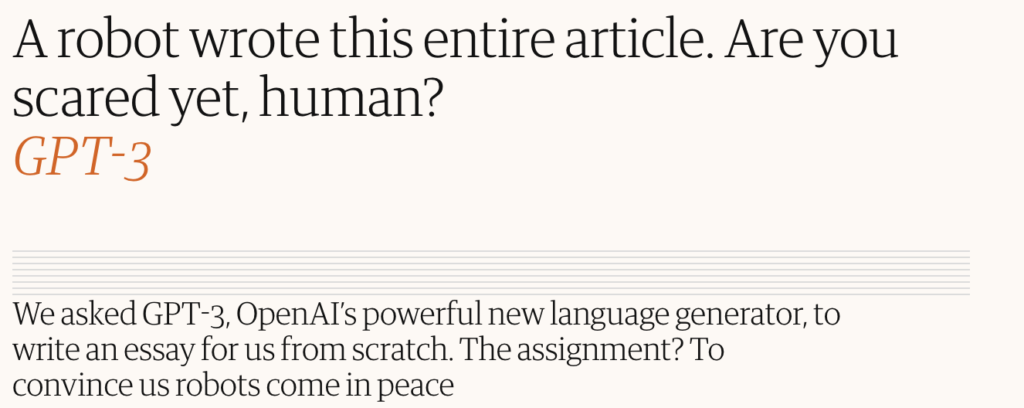
The use of bylines to credit AI authorship has caused controversy because of what’s called the “attribution fallacy,” a term coined by AI researcher Hamid Mattioli Ekbia to describe when people uncritically accept that a task was performed autonomously by AI. A byline can fall afoul of this fallacy by suggesting sole authorship by the AI agent, overstating the capability of the technology and concealing the role of human editors.
We use “interruption” to refer to any indicator that occurs during content display to explain the role of AI in manipulating or generating it. This may be during time-based media (e.g., at the opening of a video) or through delaying access to content (e.g., a pop-up notice).
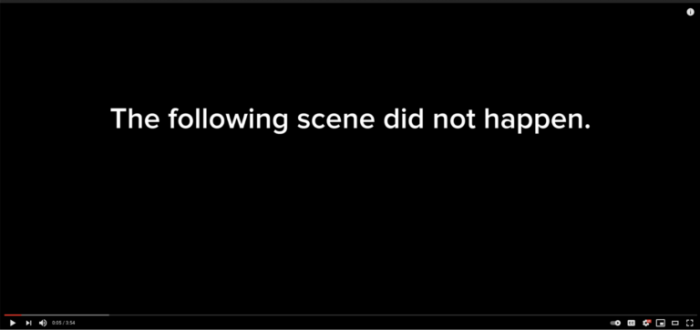
Pre-roll. In AI-manipulated video, a common tactic is to use a pre-roll label: a notice before the video starts that explains the role of AI.

Pre-roll labels have the advantage of alerting viewers to the role of AI (and more generally that the events didn’t actually occur) before someone watches the video, so they understand what they’re looking at from the start.
The problem is that this opening notice can very easily be edited out and the video reshared as if it were real.
Reveal. A reveal is the opposite of a pre-roll: It tells viewers after they’ve watched a video that it has been AI-manipulated.
The reveal can have great dramatic effect, inducing a state of surprise and awe in the viewer. This can help to emphasize a point, such as the believability of the deepfake.
This is a common tactic. But, even if well-intended, it involves a form of temporary deception, aiming to trick the viewer. This has the risk of being recalled later on as real if this is how it was initially understood. It also relies on someone making it to the end of the video (many people just watch the opening on social media). And, similar to the pre-roll, a reveal is easily edited out.
Interstitial. Interstitial labels interrupt media one or more times to notify the audience of something. This is most commonly used in advertising; longer YouTube videos, for example, use interstitial ads, as do many podcasts. Interstitial labels would make it harder for audiences to ignore or forget the message; harder to join too late or too early and miss it; and harder to edit out the alert.
We have only seen a few of these in the wild (see example from “The Late Show with Stephen Colbert”). We have spoken to technology companies that are conducting internal research on interstitial labels, and are encouraging them to share their findings regarding the impact of those labels more publicly.

We use “annotation” to refer to anything that highlights discrete parts of content, such as areas of an image, durations of a video, or sections of a text.
Annotation. Annotation refers to highlighting specific features of media to indicate where AI manipulation has occurred. This might include highlighting parts of a video that have been manipulated, or could involve narrating over and between snippets of synthetic audio.
1) Ears are nightmare factories, just totally butchered
2) Light source different in the two eyes
3) Teeth are bizarre / wrong
4) Nose just off with nostril and tip of the nose
5) Background is really messed up on the left side— Aric Toler (@AricToler) June 17, 2020
Annotation is embedded in detection technologies and used by journalists as it provides a tool for precise explanation. This works well for those whose primary subject is the manipulation, but less useful for those who want to focus on content.
One risk is that the degree of confidence implied by precise, thin lines — a common technique of many commercial deepfake detectors — may inspire false confidence that something is AI-manipulated. Such a conclusion, in high-stakes environments, could have real-world impact.
Side-by-side. Side-by-side is another emerging tactic in journalism. It places an unmanipulated piece of media next to manipulated media for comparison by the user.

This tactic allows the viewer to discern the manipulation through comparison. It is also less reliant on long textual explanations, and gives an instinctive feel.
This has been used to explain non-AI manipulation of videos, such as the doctored Nancy Pelosi videos of 2019. It could also be deployed in audio, playing an authentic snippet followed by a manipulated version.
Typography. When it comes to writing, typography — fonts, for example — offer a way to isolate AI-generated elements. We see this in The Pudding’s part-GPT-3-generated essay “Nothing Breaks like an A.I. Heart,” where AI-generated text is highlighted in a sans serif font (the same tactic used in the part-GPT-3-generated book Pharmako-AI).

This method has the advantage of identifying specific components that are AI-generated in a way that will still be visible when screenshotted and shared. It can also be a way to make the AI manipulation interactive: in The Pudding’s essay, you can click a button to re-generate new text from GPT-3.
“Speculation” refers to the space created for guesses, suggestions and debate about the role of AI media when it isn’t authoritatively labeled.
Another way of looking at the question of labeling AI is what happens when you don’t label media at all. Often a lack of labels creates a kind of data deficit, ushering in speculation. Often this occurs in the comments, with viewers offering their guesses as to whether a piece of media has been manipulated with AI. It could also occur within news articles, blogs or social media posts.
We cannot eradicate speculation, but it is important to recognize the role that labels — or their absence — play in the dynamic of speculation that accompanies videos suspected of being AI-manipulated. This is especially relevant in the context of AI, where our understanding of what is and isn’t possible is constantly being challenged and reset. We further explore risks like these in the second part of this series.
Many uses of AI to manipulate media are, of course, not labeled at all, and perhaps both creators and audiences have little interest in knowing the role of AI media. After all, AI plays some kind of role in almost everything we see online.
One of the most common examples is the iPhone’s “portrait mode,” which uses AI to synthesize a shallow depth of focus by blurring what it detects as the background. This can give the impression that the photo was taken by an expensive SLR camera (though increasingly is suggestive of the iPhone’s portrait mode or another blurring filter).
Examples such as these raise an obvious question: When is it necessary to identify content as being AI-manipulated?
We have discovered numerous indicators people and organizations are using to explain the role of AI in the production of content (images, videos, audio or text). To summarize, we’ve grouped these methods into five categories:
We have also collated and tagged examples in an Airtable database to facilitate closer analysis and comparison. In some cases, there may be machine-readable metadata (such as Exif), but we focus here on labels that are accessible by general audiences.
Our goal with this short report is not to criticize or endorse any labeling tactic, but to discover what practices are currently in use and to explore what they offer and their limitations.
These examples inevitably raise a number of questions, tensions and trade-offs that are worth exploring. In Part 2 of this series, we’ll explore these considerations for AI indicators.
Tommy Shane is the head of impact and policy at First Draft. Emily Saltz is a user experience researcher. Claire Leibowicz leads the AI and Media Integrity Program at the Partnership on AI. This report originally ran on First Draft.




