Nieman Foundation at Harvard
 Consider Google News. Launched in 2002, it was one of the first attempts to aggregate and personalize news with algorithms — that is, step-by-step procedures that systematically process information. It even bragged on its homepage: “This page was generated entirely by computer algorithms without human editors. No humans were harmed or even used in the creation of this page.”
Consider Google News. Launched in 2002, it was one of the first attempts to aggregate and personalize news with algorithms — that is, step-by-step procedures that systematically process information. It even bragged on its homepage: “This page was generated entirely by computer algorithms without human editors. No humans were harmed or even used in the creation of this page.”
The Google News algorithm lists its criteria for ranking and grouping news articles as frequency of appearance, source, freshness, location, relevance, and diversity. Millions of times a day, the Google News algorithm is making editorial decisions using these criteria.
But in the systematic application of its decision criteria, the algorithm might be introducing bias that is not obvious given its programming. It can be easy to succumb to the fallacy that, because computer algorithms are systematic, they must somehow be more “objective.” But it is in fact such systematic biases that are the most insidious since they often go unnoticed and unquestioned.
Even robots have biases.
Any decision process, whether human or algorithm, about what to include, exclude, or emphasize — processes of which Google News has many — has the potential to introduce bias. What’s interesting in terms of algorithms though is that the decision criteria available to the algorithm may appear innocuous while at the same time resulting in output that is perceived as biased.
For example, unless directly programmed to do so, the Google News algorithm won’t play favorites when picking representative articles for a cluster on a local political campaign — it’s essentially non-partisan. But one of its criteria for choosing articles is “frequency of appearance.” That may seem neutral — but if one of the candidates in that race consistently got slightly more media coverage (i.e. higher “frequency of appearance”), that criterion could make Google News’ output appear partisan.
Algorithms may lack the semantics for understanding higher-order concepts like stereotypes or racism — but if, for instance, the simple and measurable criteria they use to exclude information from visibility somehow do correlate with race divides, they might appear to have a racial bias.
Simple decision criteria that lead to complex inclusion and exclusion decisions are one way that bias, often unwittingly, can manifest in algorithms. Other mechanisms through which algorithms introduce bias into news media can be illustrated by considering the paramount information process of summarization.
In a sense, reporting is really about summarizing reality. You might protest: “It’s also about narrative and storytelling!” — and you’d be right, since few things are more boring as a dry summary. But before the story, the reporter has to first make decisions about which events to include, what context can safely be excluded, and what to emphasize as truly mattering — all of which have the potential to tint the story with bias. Reporters observe the world and uncover a range of information, only to later prune it down to some interesting yet manageable subset that fits the audience’s available time and attention. That’s summarization.
Summarization is important because time and attention are two of the defining commodities of our age. Most of us don’t want or need the intricate details of every story; we’re often happy to instead have a concise overview of an event. This need to optimize attention and save us from the information glut is driving new innovations in how information gets processed and summarized, both in editorial processes as well as new computing algorithms.
Circa is a startup in San Francisco working on an editorial process and mobile app which summarizes events into a series of “points” or factoids. They employ editors to collect “facts from a variety of sources” and convert them into “concise, easy-to-read ‘points’ in Circa,” as explained in their app’s help pages. To be fair, Circa thinks of themselves less as summarizers and more as storytellers who add value by stringing those concise “points” into a sequence that builds a story. The approach they use is driven by editors and is, of course, subject to all of the ways in which bias can enter into an editorial process, including both individual and organizational predilections.
But what if Circa started adding algorithms which, instead of relying on editors, made decisions automatically about which points to include or exclude? They might start looking a bit more like London-based startup Summly, which has a new reading app populated with “algorithmically generated summaries from hundreds of sources.” Summly works by choosing the most “important” sentences from an article and presenting those as the summary. But how might this algorithm start to introduce bias into the stories it outputs, for instance, through its definition of “important”? In a story about the Israeli-Palestinian conflict, say, is it possible their algorithm might disproportionately select sentences that serve to emphasize one side over the other?
We may never know how Summly’s algorithms might give rise to bias in the summaries produced; it’s a proprietary and closed technology which underscores the need for transparency in algorithms. But we can learn a lot about how summarization algorithms work and might introduce bias by studying more open efforts, such as scholarly research.
I spoke to Jeff Nichols, a manager and research staff member at IBM Research, who’s built a system for algorithmically summarizing sporting events based on just the tweets that people post about them. Nichols, a sports enthusiast, was really getting into the World Cup in 2010 when he started plotting the volume of tweets over time for the different games. He saw spikes in the volume and quickly started using his ad hoc method to help him find the most exciting parts of a game to fast forward to on his DVR. Volume spikes naturally occur around rousing events — most dramatically, goals.
From there, Nichols and his team started asking deeper questions about what kinds of summaries they could actually produce from tweets. What they eventually built was a system that could process all of the tweets around a game, find the peaks in tweet activity, select key representative tweets during those peaks, and then splice together those tweets into short summaries. They found that the output of their algorithm was of similar quality to that of manually generated summaries (also based on tweets) when rated on dimensions of readability and grammaticality.
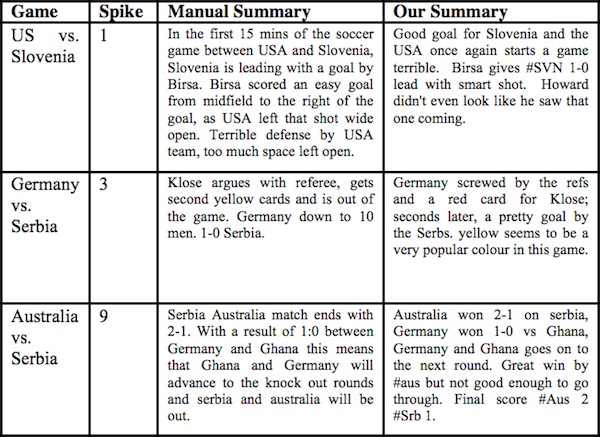
The IBM system highlights a particular bias that can creep into algorithms though: Any bias in the data fed into the algorithm gets carried through to the output of the system. Nichols describes the bias as “whoever yells the loudest,” since their relatively simple algorithm finds salient tweets by looking at the frequency of key terms in English. The implications are fairly straightforward: If Slovenia scores on a controversial play against the U.S., the algorithm might output “The U.S. got robbed” if that’s the predominant response in the English tweets. But presumably that’s not what the Slovenians tweeting about the event think about the play. It’s probably something more like, “Great play — take that U.S.!” (In Slovenian of course). Nichols is interested in how they might adapt their algorithm to take advantage of different perspectives and generate purposefully biased summaries from different points of view. (Could be a hit with cable news!)
In making decisions about what to include or exclude in a summary, algorithms usually have to go through a step which prioritizes information. Things with a lower priority get excluded. The IBM system, for example, is geared towards “spiky” events within sports. This generally works for finding the parts of a game that are most exciting and which receive a lot of attention. But there are other interesting stories simmering below the threshold of “spikiness.” What about the sweeper who played solid and consistent defense but never had a key play that garnered enough tweets to get detected by the algorithm? That part of the event, of the story, would be left out.
The IBM algorithm not only prioritizes information but it also has to make selections based on different criteria. Some of these selections can also be encoded as heuristics, which the algorithm’s creators embed to help the algorithm make choices. For instance, the IBM system’s programmers set the algorithm to prefer longer rather than shorter tweets for the summary, since the shorter tweets tended to be less-readable sentence fragments. That’s certainly a defensible decision to make, but Nichols acknowledges it could also introduce a bias: “Not picking comments from people who tend not to write in complete sentences could perhaps exclude an undereducated portion of the population.” This highlights the issue that the criteria chosen by programmers for selection or prioritization may correlate with other variables (e.g. education level) that could be important from a media bias point of view.
Summarization is just one type of information process that can be systematized in an algorithm. In your daily news diet, it’s likely that a variety of algorithms are touching the news before you even lay eyes on it. For example, personalization algorithms like those used by Zite, the popular news reading application, systematically bias content towards your interests, at the expense of exposing you to a wider variety of news. Social Flow is a startup in New York that uses optimization algorithms to determine the exact timing of when to share news and content on social networks so that it maximally resonates with the target audience. Optimization algorithms can also be used to determine the layout of a news page. But optimizing layout based on one criteria, like number of pageviews, might have unintended consequences, like consistently placing scandals or celebrity news towards the top of the page. Again, the choice of what metrics to optimize, and what they might be correlated with, can have an impact.
Another class of algorithms that is widespread in news information systems is ranking algorithms. Consider those “top news” lists on most news homepages, or how comments get ranked, or even how Twitter ranks trends. Twitter trends in particular have come under some scrutiny after events that people thought should appear, like #occupywallstreet or #wikileaks, didn’t trend. But, like Summly, Twitter is not transparent about the algorithm it uses to surface trends, making it hard to assess what the systematic biases in that algorithm really are and whether any heuristics or human choices embedded in the algorithm are also playing a role.
Google also uses ranking algorithms to sort your search results. In this case, the ranking algorithm is susceptible to the same type of “whoever yells the loudest” bias we heard about from Nichols. The Internet is full of SEO firms trying to game Google’s algorithm so that certain content will appear high in search results even if, perhaps, it doesn’t deserve to be there. They do this in part by associating certain keywords with the target site and by creating links from many other sites to the target site. There are others who seek to manipulate search rankings. Takis Metaxis, a professor at Wellesley College, with colleague Eni Mustafaraj has written about “googlebombing,” the act of creating associations between political actors, such as George W. Bush, with a negative search term, like “miserable failure,” so that the person shows up when that phrase is searched for. This is a perfect example of how biasing the data being fed into an algorithm can lead to a biased output. And when the data feeding into an algorithm is public, the algorithm is left open to manipulation.
Not all algorithmic bias has to be detrimental. In fact, if algorithms could somehow balance out the individual or cognitive biases that each of us harbor, this could positively impact our exposure to information. For instance, at the Korea Advanced Institute of Science and Technology (KAIST), Souneil Park and his collaborators have been experimenting with aggregation algorithms that feed into a news presentation called NewsCube, which nudges users towards consuming a greater variety of perspectives. Forget leaving things to chance with serendipity — their research is working on actively biasing your exposure to news in a beneficial way. Richard Thaler and Cass Sunstein, in their book Nudge, call this kind of influence “libertarian paternalism” — biasing experiences to correct for cognitive deficiencies in human reasoning. Not only can algorithms bias the content that we consume — someday they might do so in a way that makes us smarter and less prone to our own shortcomings in reasoning. Perhaps an algorithm could even slowly push extremists towards the center by exposing them to increasingly moderate versions of their ideas.
Algorithms are basically everywhere in our news environment, whether it’s summarization, personalization, optimization, ranking, association, classification, aggregation, or some other algorithmic information process. Their ubiquity makes it worth reflecting on how these processes can all serve to systematically manipulate the information we consume, whether that be through embedded heuristics, the data fed into them, or the criteria used to help them make inclusion, exclusion, and emphasizing decisions.
Algorithms are always going to have to make non-random inclusion, exclusion, and emphasizing decisions about our media in order to help solve the problem of our limited time and attention. We’re not going to magically make algorithms “objective” by understanding how they introduce bias into our media. But we can learn to be more literate and critical in reading computational media. Computational journalists in particular should get in the habit of thinking deeply about what the side effects of their algorithmic choices may be and what might be correlated with any criteria their algorithms use to make decisions. In turn, we should be transparent about those side effects in a way that helps the public judge the authority of our contributions.
Nick Diakopoulos is a NYC-based consultant specializing in research, design, and development for computational media applications. His expertise spans human-computer interaction, data visualization, and social media analytics. You can find more of his research online at his website.




